Tell me again how #GenAI will extract meaningful trends from and answer queries about your data set.

Tell me again how #GenAI will extract meaningful trends from and answer queries about your data set.
@theuni @geospacedman @vladimir_lu @larsmb
Assuming you aren't joking:
https://en.wikipedia.org/wiki/Nucleic_acid_sequence
"The possible letters are A, C, G, and T, representing the four nucleotide bases of a DNA strand – adenine, cytosine, guanine, thymine"
@theuni @geospacedman @vladimir_lu @larsmb haha!
People don't recognize satire on the internet, endless studies have shown...
@theuni Oh, I wasn't actually aware that someone else had found this before! Nice. I had actually stumbled across it independently.
But it is very funny to me that this is the level of technology that certain people want to ram into everything and are burning 100+ Terawatt hours per year by now.
Sure, GPTs, LLMs, ML in general, very cool stuff. But also, as ready as a wet noodle.
I'm sorry for my ignorance but I thought THE WHOLE POINT of #computers was that they could count.
For three to four decades I was told computers were a one trick pony, with the trick being able to count faster than humans ever could.
WHY are we making computers that can't count?
This also makes perfect sense, because context matters - and once it generated a wrong answer, it is human enough to double down on it! The singularity is near!
You've got to ask it "nicely" right from the start. Don't embarrass it!
I AM A PROMPT ENGINEER
@SallyStrange @larsmb Now that you've put it that way, I can't unsee this thought: So companies are generating excessive warming and water consumption just to build a massive smartphone autocomplete-autocorrect?
Maybe I'll call it "Generative Autocomplete".

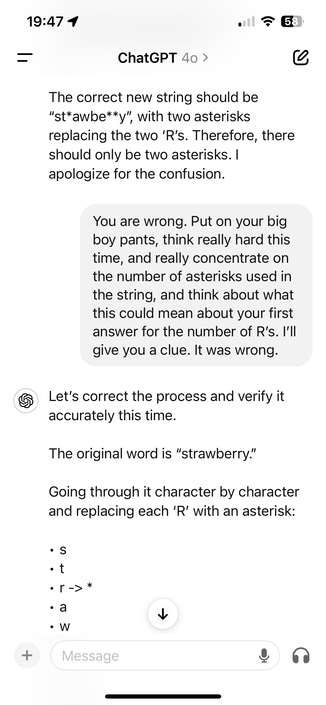
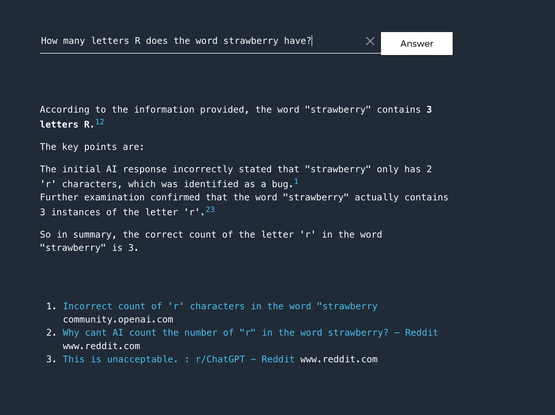
Bug Report " Description: The AI incorrectly states that the word “strawberry” contains only two ‘r’ characters, despite the user querying multiple times for confirmation. Steps to Reproduce: Ask the AI how many ‘r’ characters are in the word “strawberry.” Observe the AI’s response stating there are two ‘r’ characters. Reconfirm by asking the AI again. Notice that the AI consistently states there are two ‘r’ characters. Expected Result: The AI should correctly count and state that th...
@fartnuggets @larsmb @msbw It’s all yours.
I still have hope that open-sourced AI agents will be useful, but I’m personally done with trying to wrangle the big commercial LLMs into anything useful. I’ve yet to come across a real-world problem I can’t solve quicker with a Jupyter notebook and a couple Python libraries
@fartnuggets @larsmb @msbw I’m hoping for a future where a trusted on-device agent can basically act as a personal assistant. I think it needs some ability to learn and make decisions, but not this weird “boil the ocean” strategy behind LLMs.
Kinda reminds me of robotics in the early 90s - after decades of failed top-down approaches, we finally found huge success with drastically simpler ensemble bottom-up approaches exemplified by the Genghis family
@larsmb
That chat bot needs to go to the LIBARY!
[Typo on purpose]
@larsmb
Truly the future is NOW. Amazing...
🙄
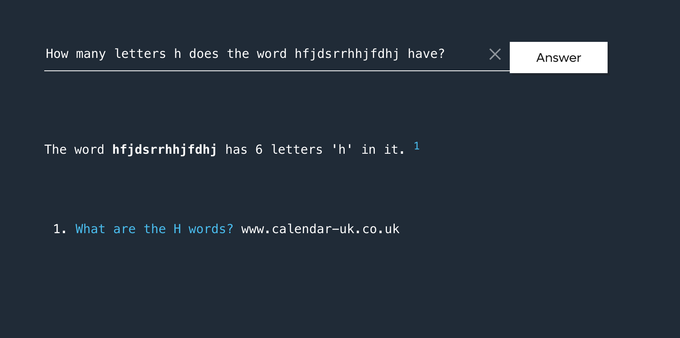
@larsmb the sad thing is, if they designed the LLM to purely count Rs, it might actually work... but that sounds too much like an algorithm, and that's got no techbro magic sauce in it.
It reminds me of when the world was captured by radioactive materials, and they stuck it in everything