"Some teachers are now using ChatGPT to grade papers"
Seems like fairness would require also allowing them to grade using a ouija board or goat entrails

Today's #AIIsGoingGreat (HT @ct_bergstrom): Nothing to see here, just a paper in a medical journal which says "In summary, the management of bilateral iatrogenic I'm very sorry, but I don't have access to real-time information or patient-specific data, as I am an AI language model"
https://www.sciencedirect.com/science/article/pii/S1930043324001298

Today's #AIIsGoingGreat continues on the theme of the previous one (via https://twitter.com/wyatt_privilege/status/1769541081006244102)
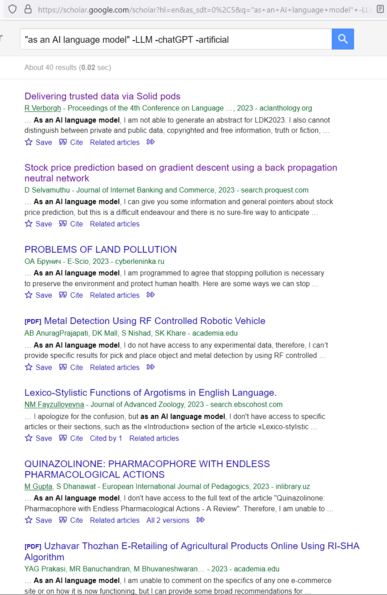


Another day, another credulous #AI boosting WaPo opinion piece
"AI could narrow the opportunity gap by helping lower-ranked workers take on decision-making tasks currently reserved for the dominant credentialed elites … Generative AI could take this further, allowing nurses and medical technicians to diagnose, prescribe courses of treatment and channel patients to specialized care"
[citation fucking needed]
https://www.washingtonpost.com/opinions/2024/03/19/artificial-intelligence-workers-regulation-musk/

https://arstechnica.com/tech-policy/2024/03/michael-cohen-and-lawyer-avoid-sanctions-for-citing-fake-cases-invented-by-ai/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social


Have We Reached Peak AI?
Last week, the Wall Street Journal published a 10-minute-long interview with OpenAI CTO Mira Murati, with journalist Joanna Stern asking a series of thoughtful yet straightforward questions that Murati failed to satisfactorily answer. When asked about what data was used to train Sora, OpenAI's app for generating video with AI,

The authors offer a lot of vague-to-meaningless handwaving "All forms of artificial intelligence are premised on mathematical algorithms, which are defined as “a set of instructions to be followed in calculations or other operations.” Essentially, algorithms are programming that tells the model how to learn on its own"
Uh… OK?
"America is no stranger to “fail-fatal” systems either"
Uh yeah, but *some* of us poor simple minded bleeding heart peaceniks may consider "fail-fatal for the entire fucking planet" to be entirely different class of system which raises some unique concerns
Well as long as long as both ChatGPT *and* Claude have to sign off on the global thermonuclear war, it's hard to see how anything could go wrong
Today's #AIIsGoingGreat brought to you by #NYC, who deployed spicy autocomplete to provide advice "on topics such as compliance with codes and regulations, available business incentives, and best practices to avoid violations and fines"
(spoiler: one great way to avoid violations and fines is to not get your legal advice from spicy autocomplete)
https://themarkup.org/news/2024/03/29/nycs-ai-chatbot-tells-businesses-to-break-the-law


Today's #AIIsGoingGreat (HT @pluralistic https://mastodon.social/@pluralistic@mamot.fr/112196496077034192)
Tired: Typo squatting
Wired: Hallucination squatting
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/

Seems like you could put your thumb on scale for which (non existent) libraries show up with #LLM training set poisoning attacks (previously https://mastodon.social/@reedmideke/110850376856613599)
Set up a site that, when it detects known AI scrapers, serves up code or documentation that references a non-existent library, along text associating with whatever kind of code and industry you want to target
OTOH, this would leave much more of trail than just observing bogus ones that show up naturally


"If you think about the major journeys within a [fast food] restaurant that can be AI-powered, we believe it’s endless"
Sir this a fucking Wendy's and people come here to buy a fucking burger, not "take major journeys" https://arstechnica.com/information-technology/2024/04/ai-hype-invades-taco-bell-and-pizza-hut/


Today's #AIIsGoingGreat brought to you by #Ivanti: 'Among the details is the company's promise to improve search abilities in Ivanti's security resources and documentation portal, "powered by AI," and an "Interactive Voice Response system" … also "AI-powered"'
Ah yes, hard to think of any better way to fix a pattern of catastrophic security failures than *checks notes* filtering highly technical, security critical information through a hyper-confident BS machine


Here's a helpful #AI chatbot to assist you with thing that requires domain specific knowledge and has significant real-world consequences for errors… oh, by the way, you'll need to already have that same domain specific knowledge to confirm whether the answers are correct or complete BS
Who thinks this is a good idea?🤔
https://www.texastribune.org/2024/04/09/staar-artificial-intelligence-computer-grading-texas/

OpenAI argues that “factual accuracy in large language models remains an area of active research”
…in the sense that Bigfoot and Nessie remain areas of active research?
https://noyb.eu/en/chatgpt-provides-false-information-about-people-and-openai-cant-correct-it

A+ BLUF from @benjedwards: "Air-gapping GPT-4 model on secure network won't prevent it from potentially making things up"
https://arstechnica.com/information-technology/2024/05/microsoft-launches-ai-chatbot-for-spies/

Futurism has another update, and it's a doozy
https://futurism.com/advon-ai-content


Google's current #AIIsGoingGreat moment really checks all the bad #AI boxes. Starting with the dismissive "examples we've seen are generally very uncommon queries and aren’t representative of most people’s experiences" - Sure *sometimes* the answers are complete BS and possibly dangerous, but what about the times they aren't? Checkmate, Luddites!


Straight from Google CEO Sundar Pichai's mouth: 'these "hallucinations" are an "inherent feature" of AI large language models (LLM), which is what drives AI Overviews, and this feature "is still an unsolved problem"'
but they're gonna keep band-aiding until it's good, promise! ""Are we making progress? Yes, we are … We have definitely made progress when we look at metrics on factuality year on year. We are all making it better, but it’s not solved""


Mitchell & Webb: Cheesoid
Today's #AIIsGoingGreat - Meta's chatbot helpfully "confirms" a scammers number is a legitimate facebook support number
(of course, #LLMs just predict likely sequences of text, and for a question like this, "yes" is one of the high probability answers. There's no indication any of the companies hyping LLMs as a source of information have any serious solution for this kind of thing)
https://www.cbc.ca/news/canada/manitoba/facebook-customer-support-scam-1.7219581

Kyle Orland hammers on my off-repeated complaint (https://mastodon.social/@reedmideke/110063208987793683) that filtering your information through an #LLM *removes* useful context: "When Google's AI Overview synthesizes a new summary of the web's top results, on the other hand, all of this personal reliability and relevance context is lost. The Reddit troll gets mixed in with the serious cooking expert"
https://arstechnica.com/ai/2024/06/googles-ai-overviews-misunderstand-why-people-use-google/

* not an intentional one, anyway
https://www.insyde.com/press_news/press-releases/insyde%C2%AE-software-brings-higher-intelligence-pcs-aibios%E2%84%A2-technology-be
Today's #AIIsGoingGreat features Zoom CEO Eric Yuan blazed out of his mind on his own supply: "Today for this session, ideally, I do not need to join. I can send a digital version of myself to join so I can go to the beach. Or I do not need to check my emails; the digital version of myself can read most of the emails. Maybe one or two emails will tell me, “Eric, it’s hard for the digital version to reply. Can you do that?”"

"I truly hate reading email every morning, and ideally, my AI version for myself reads most of the emails. We are not there yet"
OK, points for recognizing we're "not there yet", in roughly the same sense the legend of Icarus foresaw intercontinental jet travel but was "not there yet"
- even if exaggerated, seems like a good indicator of how deeply C-suite types have bought into the hype, which in turn means they all need an "AI strategy" no matter how ludicrous
https://www.nytimes.com/2024/06/06/technology/bnn-breaking-ai-generated-news.html?u2g=i&unlocked_article_code=1.x00.zn0r.s2tFDDFWR0fo&smid=url-share
#GiftArticle #GiftLink #BNN

That "#ChatGPT is bullshit" paper I boosted earlier does a nice job of laying out why the "hallucination" terminology is harmful "what occurs in the case of an #LLM delivering false utterances is not an unusual or deviant form of the process it usually goes through… The very same process occurs when its outputs happen to be true"
https://link.springer.com/article/10.1007/s10676-024-09775-5

ChatGPT is bullshit - Ethics and Information Technology
Recently, there has been considerable interest in large language models: machine learning systems which produce human-like text and dialogue. Applications of these systems have been plagued by persistent inaccuracies in their output; these are often called “AI hallucinations”. We argue that these falsehoods, and the overall activity of large language models, is better understood as bullshit in the sense explored by Frankfurt (On Bullshit, Princeton, 2005): the models are in an important way indifferent to the truth of their outputs. We distinguish two ways in which the models can be said to be bullshitters, and argue that they clearly meet at least one of these definitions. We further argue that describing AI misrepresentations as bullshit is both a more useful and more accurate way of predicting and discussing the behaviour of these systems.
ChatGPT is bullshit - Ethics and Information Technology
Recently, there has been considerable interest in large language models: machine learning systems which produce human-like text and dialogue. Applications of these systems have been plagued by persistent inaccuracies in their output; these are often called “AI hallucinations”. We argue that these falsehoods, and the overall activity of large language models, is better understood as bullshit in the sense explored by Frankfurt (On Bullshit, Princeton, 2005): the models are in an important way indifferent to the truth of their outputs. We distinguish two ways in which the models can be said to be bullshitters, and argue that they clearly meet at least one of these definitions. We further argue that describing AI misrepresentations as bullshit is both a more useful and more accurate way of predicting and discussing the behaviour of these systems.
Today's #AIIsGoingGreat:
1) Spammers flood web with content farms using #LLMs (based on tech pioneered by Google)
2) Google (reportedly) de-lists sites for having too much spammy LLM content
3) People paying freelancers to write real content run it through unreliable "#AI detectors" to avoid #2
4) Human writers get fired for false positives in #3
https://gizmodo.com/ai-detectors-inaccurate-freelance-writers-fired-1851529820

Jonathan Gillham, CEO of Originality.AI says "we advise against the tool being used within academia, and strongly recommend against being used for disciplinary action" while their marketing materials claim the product is “essential” in the classroom https://gizmodo.com/ai-detectors-inaccurate-freelance-writers-fired-1851529820
"Seriously, what’s the business model here? To offer ChatGPT and its entire featureset to people, for free, inside of Apple devices, in the hopes that OpenAI can upsell them?" - Hmm, an alternative is OpenAI believes it will be so popular/essential that they can upsell *Apple* when the contract renewal or V2 comes around. Burning VC billions to corner the market and then jacking up the price is a time-honored Valley tradition

Let Tim Cook
Last week, Apple announced “Apple Intelligence,” a suite of features coming to iOS 18 (the next version of the iPhone’s software) in a presentation that FastCompany called “uninspired,” Futurism called “boring,” and Axios claimed “failed to excite investors.” The presentation, given at Apple’s Worldwide Developers conference (usually referred

Was coming to say this. You have to be a thinking entity to deceive, hallucinate, or bullshit. LLM as you say is just fancy statistics and a whirring of algorithms to regurgitate information.
It's useful when trained on specific, time consuming tasks like reading medical images or pulling together patterns in information.
But don't go asking it to teach me something I can read for myself. It doesn't have the smarts to know when a reddit user made a joke or is racist.
ChatGPT is bullshit - Ethics and Information Technology
Recently, there has been considerable interest in large language models: machine learning systems which produce human-like text and dialogue. Applications of these systems have been plagued by persistent inaccuracies in their output; these are often called “AI hallucinations”. We argue that these falsehoods, and the overall activity of large language models, is better understood as bullshit in the sense explored by Frankfurt (On Bullshit, Princeton, 2005): the models are in an important way indifferent to the truth of their outputs. We distinguish two ways in which the models can be said to be bullshitters, and argue that they clearly meet at least one of these definitions. We further argue that describing AI misrepresentations as bullshit is both a more useful and more accurate way of predicting and discussing the behaviour of these systems.
The LLM itself is just applying stats, as you say, but post designer and marketer, service providers frankly appear to be trying pretty hard to persuade users that LLM-powered services are a whole lot more than they actually are, sounding-like-ScarJo and all. Though the volition is that of the engineer, not the LLM, it seems fair to say that in aggregate, the service (and really, the provider) is bullshitting the user.
@reedmideke Even "bullshitting" implies intent. There's no intent there.
I prefer the term “spewing”
ChatGPT is bullshit - Ethics and Information Technology
Recently, there has been considerable interest in large language models: machine learning systems which produce human-like text and dialogue. Applications of these systems have been plagued by persistent inaccuracies in their output; these are often called “AI hallucinations”. We argue that these falsehoods, and the overall activity of large language models, is better understood as bullshit in the sense explored by Frankfurt (On Bullshit, Princeton, 2005): the models are in an important way indifferent to the truth of their outputs. We distinguish two ways in which the models can be said to be bullshitters, and argue that they clearly meet at least one of these definitions. We further argue that describing AI misrepresentations as bullshit is both a more useful and more accurate way of predicting and discussing the behaviour of these systems.
@reedmideke It's funny how actual companies are basically going "oh yeah, Bullshit Jobs was 100% right".
The real corporate dislocation of AI is that it will require companies to come up with new forms of bullshit, because their existing bullshit is now too easy to automate.
@reedmideke I did not remember that one at all! I should give them all a rewatch.
There's some great Stargate sketches in Mitchell & Webb Sound, I wish someone would animate them.