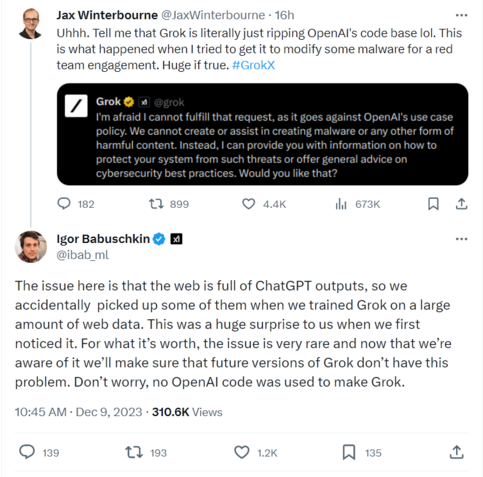
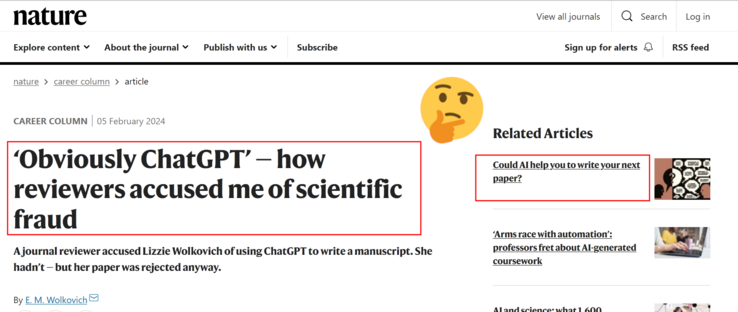
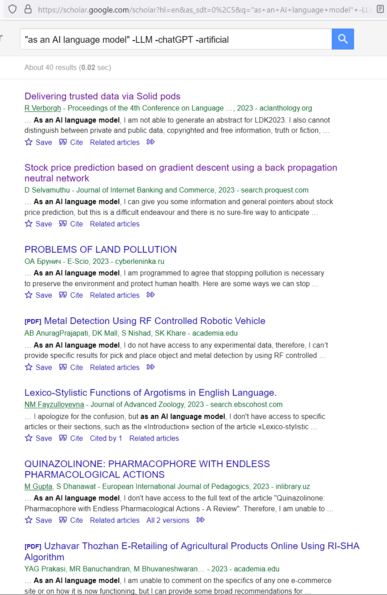
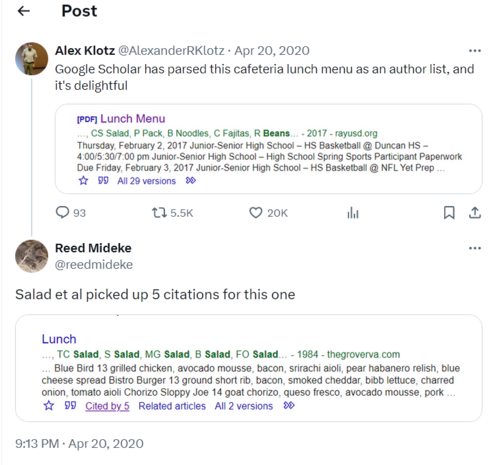
"Chat alignment hides memorization" - Note *hides*, not *prevents*
As the authors also note, OpenAI "fixed" this by preventing the particular problematic prompt, but "Patching an exploit != Fixing the underlying vulnerability"
https://not-just-memorization.github.io/extracting-training-data-from-chatgpt.html