Oh and if anyone is looking for other outlets to check for "we pinky swear it's not #AI" churnalism, #AdVon helpfully gives you a list of high profile clients (claimed; lying or exaggerating about having big name customers is an extremely common SV startup tactic) https://advoncommerce.com/

Data point for the "LLMs can't infringe copyright because they don't contain or produce verbatim copies" crowd https://www.404media.co/google-researchers-attack-convinces-chatgpt-to-reveal-its-training-data/

Google Researchers’ Attack Prompts ChatGPT to Reveal Its Training Data
ChatGPT is full of sensitive private information and spits out verbatim text from CNN, Goodreads, WordPress blogs, fandom wikis, Terms of Service agreements, Stack Overflow source code, Wikipedia pages, news blogs, random internet comments, and much more.
"Chat alignment hides memorization" - Note *hides*, not *prevents*
As the authors also note, OpenAI "fixed" this by preventing the particular problematic prompt, but "Patching an exploit != Fixing the underlying vulnerability"
https://not-just-memorization.github.io/extracting-training-data-from-chatgpt.html

Can't be certain without more specifics but color me extremely skeptical that "#AI" producing thousands of targets is doing much more the laundering responsibility

New #ChatGPTLawyer dropped. Much like the ones in NY (Mata v. Avianca), it made up citations, he didn't check, and then doubled down when caught, initially blaming it on an intern
https://www.coloradopolitics.com/courts/disciplinary-judge-approves-lawyer-suspension-for-using-chatgpt-for-fake-cases/article_d14762ce-9099-11ee-a531-bf7b339f713d.html
https://www.coloradopolitics.com/courts/disciplinary-judge-approves-lawyer-suspension-for-using-chatgpt-for-fake-cases/article_d14762ce-9099-11ee-a531-bf7b339f713d.html

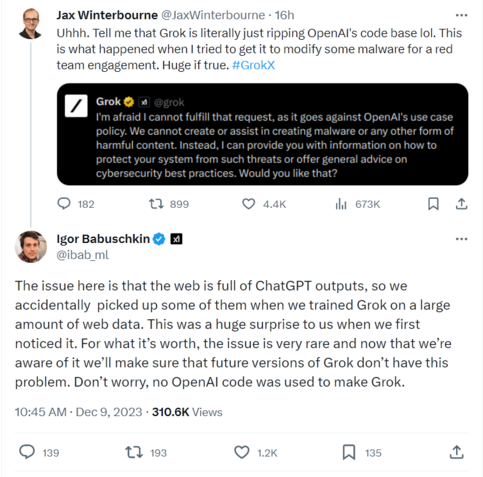
This hilarious in its own right, but it's also a great illustration of how people get tripped up by #LLM #AI bullshitting: One would expect an "AI" to at least know which brand AI it is, but of course, these LLMs don't actually know anything
Also the classic AI vendor response of promising to fix this particular case without any hint of acknowledging the underlying problem
Begging news orgs to stop reporting #AI company pitch decks as fact "Ashley [the bot] analyzes voters' profiles to tailor conversations around their key issues. Unlike a human, Ashley always shows up for the job, has perfect recall of all of Daniels' positions"
"…is now armed with another way to understand voters better, reach out in different languages (Ashley is fluent in over 20)"
"As far as the Court can tell, none of these cases exist" - The #ChatGPTLawyer / Trump world crossover no one asked for? https://arstechnica.com/tech-policy/2023/12/michael-cohens-lawyer-cited-three-fake-cases-in-possible-ai-fueled-screwup/

Another article on reported Israeli AI targeting greatly hindered by the lack of any specifics (what kinds of intelligence, what kinds of targets, for starters). Not a knock on NPR, obviously little is public
It certainly *sounds* like some of the horrifically bad systems we've seen promoted in other contexts, and the results certainly don't appear to contradict that, but hard to say much beyond that…
Key point IMO in the @willoremus #AI story, after noting Microsoft "fixed" some of the problematic results, one of the researchers says "The problem is systemic, and they do not have very good tools to fix it" - You can't bandaid your way from a BS machine with no concept of truth into a reliable source of information, so the fact that biggest players in the industry keep bandaiding should call the entire #LLM hype cycle into question

Man, link in that post I boosted from @Chloeg (https://mastodon.art/@Chloeg/111620626442103902) is a perfect example of #LLM #AI enshittification. Get a domain, put up a wordpress site with AI generated glop on a some popular topic, run as many garbage ads as possible. Sure it's the information equivalent of dumping raw sewage in the local river, but none of it is illegal or a serious violation of any TOS, and overhead must be extremely low
Archive link https://web.archive.org/web/20231222025203/https://www.learnancientrome.com/did-ancient-rome-have-windows/
Chloe Gilbert Artist (@[email protected])
Ok so im reading this article on Roman Glazing and slowly I begin to realise that it was written by an AI. Witness the section on “What existed before windows” where it suddenly starts talking about MS-DOS…. https://www.learnancientrome.com/did-ancient-rome-have-windows/
WaPo has done some good #AI reporting, but this opinion piece from Josh Tyrangiel ain't it…
"The most obvious thing is that they’re not hallucinations at all"
Good start…
"Just bugs specific to the world’s most complicated software."
Uh no, literally the opposite of that that, FFS 😬
https://www.washingtonpost.com/opinions/2023/12/27/artificial-intelligence-hallucinations/

So according to Cohen, he got bogus legal citations from #GoogleBard, didn't check them, and passed them to his lawyer, who also didn't check them. Which, I dunno, seems pretty negligent all around even if you didn't know Bard was a bullshit generator https://www.washingtonpost.com/technology/2023/12/29/michael-cohen-ai-google-bard-fake-citations/

Also raises the suspicion Cohen was doing a significant amount of the work and just having his lawyer put his name on it because Cohen is disbarred (though presumably Cohen could have gone pro se if he really wanted to). Anyway, I predict they're gonna continue the #ChatGPTLawyer sanctions streak
"ChatGPT bombs test on diagnosing kids’ medical cases" OK, but did they also test a magic 8 ball? Reading goat entrails?
https://arstechnica.com/science/2024/01/dont-use-chatgpt-to-diagnose-your-kids-illness-study-finds-83-error-rate/
https://arstechnica.com/science/2024/01/dont-use-chatgpt-to-diagnose-your-kids-illness-study-finds-83-error-rate/

Another data point for the "LLMs can't infringe copyright because they don't contain or produce verbatim copies" crowd https://spectrum.ieee.org/midjourney-copyright

"Even when using such prompts, our models don’t typically behave the way The New York Times insinuates, which suggests they either instructed the model to regurgitate or cherry-picked their examples from many attempts" - I don't *typically* engage in large scale plagiarism, so accusing me of these specific instances of large scale plagiarism is cherry-picking! https://www.theverge.com/2024/1/8/24030283/openai-nyt-lawsuit-fair-use-ai-copyright

"OpenAI claims it’s attempted to reduce regurgitation from its large language models and that the Times refused to share examples of this reproduction before filing the lawsuit." - Per usual (https://mastodon.social/@reedmideke/111585837264775808) OpenAI would love to apply bandaids to specific instances identified by well-resourced organizations, because they know the underlying cause can't be fixed without destroying their business model
Thing that gets me about this "amazon listings with #ChatGPT error messages" story is, how do you get to the point where this is significant cost savings? Are they just using it for translation? Or are the listing just pure scams and there's no real product? https://arstechnica.com/ai/2024/01/lazy-use-of-ai-leads-to-amazon-products-called-i-cannot-fulfill-that-request/

"CEOs say generative AI will result in job cuts in 2024"
Will this include said CEOs when their hamfisted attempts to use spicy autocomplete for "banking, insurance, and logistics" predictably go off the rails, or nah? 🤔
https://arstechnica.com/ai/2024/01/ceos-say-generative-ai-will-result-in-job-cuts-in-2024/

"BMW had a compelling solution to the [#LLM #AI bullshitting] problem: Take the power of a large language model, like Amazon's Alexa LLM, but only allow it to cite information from internal BMW documentation about the car" 🤨
Surely this means it'll bullshit subtly about stuff in the manual, not that it won't bullshit?

"Now, one crucial disclosure to all this: I wasn't allowed to interact with the voice assistant myself. BMW's handlers did all the talking" yeah, I'm gonna go ahead and reserve judgement on the "solution" ¯\_(ツ)_/¯
The best* part of this piece is the content farmer who responded to a request for comment by bitching about how poorly his AI garbage content farm performs
* for suitably broad values etc.
https://www.404media.co/email/5dfba771-7226-48d5-8682-5185746868c4/?ref=daily-stories-newsletter

I for one am *shocked* that "have an extremely confident bullshitter summarize my search results" was not the killer app Microsoft expected

"Dean.Bot was the brainchild of Silicon Valley entrepreneurs Matt Krisiloff and Jed Somers, who had started a super PAC supporting Phillips" - Were these techbros so high on their own supply they thought a chatbot imitating their candidate was a good idea, or was it just a convenient way to funnel campaign funds into their pals pockets? ¯\_(ツ)_/¯
https://wapo.st/3ObSl0i

Key comment from NewsGuard's McKenzie Sadeghi in this @willoremus piece "But sites that don’t catch the error messages are probably just the tip of the iceberg" - for every Amazon seller who's too lazy to even check if the item description is an error message, there's gotta be some substantial number who do
I'd still like to see a deeper look at why using #LLM #AI descriptions makes economic sense for these sellers

"Sure, I can keep Thesaurus.com open in a tab all the time, but it’s packed with banner ads and annoyingly slow. Having my GPT open is better: there are no ads, and I can scroll up to my previous queries" - Notably, this has nothing to do with GPT being "#AI", it's just the general shittiness of the ad-supported web. A good thesaurus app integrated with the author's editor would appear serve their use case about as well
https://www.theverge.com/24049623/chatgpt-openai-custom-gpt-store-assistants
And it wouldn't even need to be free, they're paying for GPT and actual costs are likely subsidized by venture capital "Custom GPTs are a paid product that’s only available to users of ChatGPT Plus, ChatGPT Team, and ChatGPT Enterprise. For now, accessing custom GPTs through the GPT Store is free for paying subscribers… if I wasn’t already paying for ChatGPT Plus, I’d be happy to keep Googling alternative terms"
#LLM #AI hype and reality collide again
https://www.nature.com/articles/d41586-024-00349-5
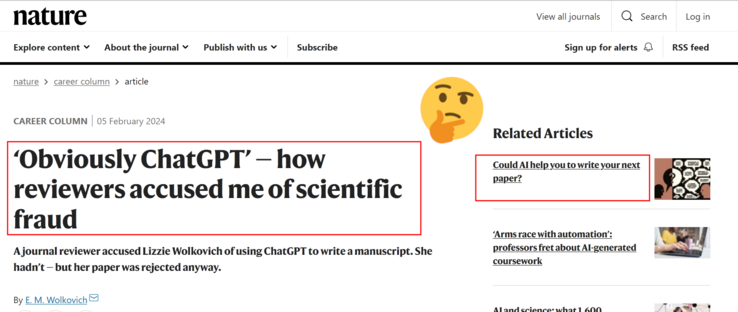

Also, from TFA "I quickly brainstormed how I might prove my case. Because I write in plain-text files [LaTeX] that I track using the version-control system Git, I could show my text change history on GitHub (with commit messages including “finally writing!” and “Another 25 mins of writing progress!”" - excellent - "Maybe I could ask ChatGPT itself if it thought it had written my paper" - Oh no, can we please get the word out LLMs BS about this just like everything else https://www.nature.com/articles/d41586-024-00349-5
Yes, if you choose to provide an #AI BS machine as a support option on your website, you may in fact be liable for the BS answers it gives to your customers
(also, if you're a multi-billion dollar company, you may avoid reputational harm by not trying to screw a person out of $650 for a ticket to their grandma's funeral ¯\_(ツ)_/¯)
https://bc.ctvnews.ca/air-canada-s-chatbot-gave-a-b-c-man-the-wrong-information-now-the-airline-has-to-pay-for-the-mistake-1.6769454

Seemingly endless parade of #ChatGPTLawyer incidents (HT @0xabad1dea for this one) really goes to show how the #AI hype is landing with the general public, despite disclaimers and cautionary tales.
Lawyers being (at least in theory) a highly educated group who know their careers depend on not putting completely made up nonsense in court filings should be less susceptible than the average person on the street, yet here we are…

Not Again! Two More Cases, Just this Week, of Hallucinated Citations in Court Filings Leading to Sanctions
For all the discussion of how generative AI will impact the legal profession, maybe one answer is that it will weed out the lazy and incompetent lawyers. By now, in the wake of several cases in which...
Admittedly one of those was pro-se with an iffy story about getting it from a lawyer, but the other was a real firm with multiple people involved ¯\_(ツ)_/¯
Another day, another #ChatGPTLawyer
"The legal eagles at New York-based Cuddy Law tried using OpenAI's chatbot, despite its penchant for lying and spouting nonsense, to help justify their hefty fees for a recently won trial"
The Court "It suffices to say that the Cuddy Law Firm's invocation of ChatGPT as support for its aggressive fee bid is utterly and unusually unpersuasive"
https://www.theregister.com/2024/02/24/chatgpt_cuddy_legal_fees/

IANAL, but whatever the merit of the other arguments "you only found the verbatim copies of your IP contained in our product because you hacked it" doesn't seem like a very compelling defense https://arstechnica.com/tech-policy/2024/02/openai-accuses-nyt-of-hacking-chatgpt-to-set-up-copyright-suit/

So my take on this is Wendy's execs decided "we need an #AI strategy!" and for reasons that remain unclear, it was somehow not immediately shot down with "Sir, this is a Wendy's, we make burgers we don't need a fuckin AI strategy"
https://www.theguardian.com/food/2024/feb/27/wendys-dynamic-surge-pricing
https://www.theguardian.com/food/2024/feb/27/wendys-dynamic-surge-pricing
"Amazon has sought to stem the tide [of #AI generated schlock books] by limiting self-publishers to three books per day" - Bruh, I know you don't want to deny the starving author toiling away on the next Great American Novel but I think we can set the bar a bit higher than that

Like start with an initial limit of one per week and have some kind of reputation threshold. If real people keep coming back to buy your dinosaur erotica or whatever, great, cap lifted, crank out as many as you can, but if you get caught impersonating or listing complete garbage, your account is nuked and you start over
Yeah, there'd be problems with straw buyers and review bombing competitors but it seems like the bar wouldn't have to be very high to make the absolute crap unprofitable
Inventor of bed shitting machine shocked to discover mountain of turds in own bed https://arstechnica.com/gadgets/2024/03/google-wants-to-close-pandoras-box-fight-ai-powered-search-spam/

WaPo has some great reporters covering the #AI beat. They also inexplicably pay Josh Tyrangiel to vomit up idiotic drivel like this
(it's also amusing they use javascript when they A/B test headlines, so sometimes it switches between the first and second one)
https://www.washingtonpost.com/opinions/2024/03/06/artificial-intelligence-state-of-the-union/



I ain't gonna waste a gift article on that shit unless someone REALLY wants it but here's a taste after you get past the Palantir hagiography "LLMs can provide better service and responsiveness for many day-to-day interactions between citizens and various agencies. They’re not just cheaper, they’re also faster, and, when trained right, less prone to error or misinterpretation"
"Some teachers are now using ChatGPT to grade papers"
Seems like fairness would require also allowing them to grade using a ouija board or goat entrails

Today's #AIIsGoingGreat (HT @ct_bergstrom): Nothing to see here, just a paper in a medical journal which says "In summary, the management of bilateral iatrogenic I'm very sorry, but I don't have access to real-time information or patient-specific data, as I am an AI language model"
https://www.sciencedirect.com/science/article/pii/S1930043324001298

Today's #AIIsGoingGreat continues on the theme of the previous one (via https://twitter.com/wyatt_privilege/status/1769541081006244102)

Should we expect better from a platform previously noted for indexing lunch menus? ¯\_(ツ)_/¯ https://twitter.com/reedmideke/status/1252450342316339207

Another day, another credulous #AI boosting WaPo opinion piece
"AI could narrow the opportunity gap by helping lower-ranked workers take on decision-making tasks currently reserved for the dominant credentialed elites … Generative AI could take this further, allowing nurses and medical technicians to diagnose, prescribe courses of treatment and channel patients to specialized care"
[citation fucking needed]
https://www.washingtonpost.com/opinions/2024/03/19/artificial-intelligence-workers-regulation-musk/

The premise is bizarre. What exactly are the non-experts doing when they "take on decision-making tasks" in this scenario? One of the big problems with current #LLM "AI" is you need subject matter expertise to tell when they are bullshitting…
Somewhat surprised Cohen's #ChatGPTLawyer escapade didn't result in sanctions for him or his lawyers, though they do seem avoided the sort of cover-up attempts that doomed some of the others
https://arstechnica.com/tech-policy/2024/03/michael-cohen-and-lawyer-avoid-sanctions-for-citing-fake-cases-invented-by-ai/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social
https://arstechnica.com/tech-policy/2024/03/michael-cohen-and-lawyer-avoid-sanctions-for-citing-fake-cases-invented-by-ai/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social

Epic Zitron rant "Sam Altman desperately needs you to believe that generative AI will be essential, inevitable and intractable, because if you don't, you'll suddenly realize that trillions of dollars of market capitalization and revenue are being blown on something remarkably mediocre" https://www.wheresyoured.at/peakai/

Have We Reached Peak AI?
Last week, the Wall Street Journal published a 10-minute-long interview with OpenAI CTO Mira Murati, with journalist Joanna Stern asking a series of thoughtful yet straightforward questions that Murati failed to satisfactorily answer. When asked about what data was used to train Sora, OpenAI's app for generating video with AI,
Can we fucking not? "In a 2019 War on the Rocks article, “America Needs a ‘Dead Hand’,” we proposed the development of an artificial intelligence-enabled nuclear command, control, and communications system to partially address this concern… We can only conclude that America needs a dead hand system more than ever" https://warontherocks.com/2024/03/america-needs-a-dead-hand-more-than-ever/

The authors offer a lot of vague-to-meaningless handwaving "All forms of artificial intelligence are premised on mathematical algorithms, which are defined as “a set of instructions to be followed in calculations or other operations.” Essentially, algorithms are programming that tells the model how to learn on its own"
Uh… OK?
"America is no stranger to “fail-fatal” systems either"
Uh yeah, but *some* of us poor simple minded bleeding heart peaceniks may consider "fail-fatal for the entire fucking planet" to be entirely different class of system which raises some unique concerns
"Keep in mind, where artificial intelligence tools are embedded in a specific system, each function is performed by multiple algorithms of differing design that must all agree on their assessment for the data to be transmitted forward. If there is disagreement, human interaction is required"
Well as long as long as both ChatGPT *and* Claude have to sign off on the global thermonuclear war, it's hard to see how anything could go wrong
Well as long as long as both ChatGPT *and* Claude have to sign off on the global thermonuclear war, it's hard to see how anything could go wrong
I don't think these guys have much chance of gaining traction in the US, but it would be unfortunate if other nuclear states decided they were at risk of an AI dead hand gap
Today's #AIIsGoingGreat brought to you by #NYC, who deployed spicy autocomplete to provide advice "on topics such as compliance with codes and regulations, available business incentives, and best practices to avoid violations and fines"
(spoiler: one great way to avoid violations and fines is to not get your legal advice from spicy autocomplete)
https://themarkup.org/news/2024/03/29/nycs-ai-chatbot-tells-businesses-to-break-the-law

One potentially informative thing reporters following up on that #NYC #AI #Chatbot story could do is #FOIA (or whatever the NY equivalent is) communications related to the acquisition and deployment. Who pushed for this in the first place? What did #Microsoft promise? What sort of quality / acceptance testing was done? Did anyone, anywhere along the line raise concerns that it would give out bad, potentially illegal advice?
I'd be pretty surprised if there isn't an email chain somewhere with a technical person going "WTF are you even thinking"
Bonus #AIIsGoingGreat "Your phone now needs more than 8 GB of RAM to run autocomplete" (and presumably, battery cost somewhat on a par with heavy GPU rendering) https://arstechnica.com/gadgets/2024/03/google-says-the-pixel-8-will-get-its-new-ai-model-but-ram-usage-is-a-concern/

Today's #AIIsGoingGreat (HT @pluralistic https://mastodon.social/@pluralistic@mamot.fr/112196496077034192)
Tired: Typo squatting
Wired: Hallucination squatting
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/

Seems like you could put your thumb on scale for which (non existent) libraries show up with #LLM training set poisoning attacks (previously https://mastodon.social/@reedmideke/110850376856613599)
Set up a site that, when it detects known AI scrapers, serves up code or documentation that references a non-existent library, along text associating with whatever kind of code and industry you want to target
OTOH, this would leave much more of trail than just observing bogus ones that show up naturally
In which the gang discovers Amazon Fresh "Just walk out" checkout was powered by Type II #AI https://gizmodo.com/amazon-reportedly-ditches-just-walk-out-grocery-stores-1851381116


@reedmideke @pluralistic a fun new spin on the create malicious package one letter off from a known package