The strain on scientific publishing 📄:
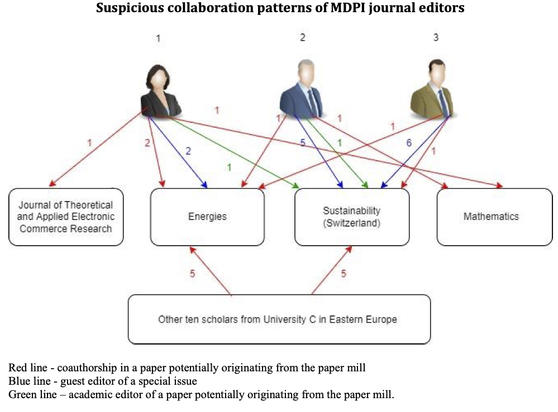
The publishing sector has a problem. Scientists are overwhelmed, editors are overworked, special issue invitations are constant, research paper mills, article retractions, journal delistings… JUST WHAT IS GOING ON!?
Myself, pablo, @paolocrosetto and Dan have spent the last few months investigating just that.
https://arxiv.org/abs/2309.15884
A thread🧵1/n
#AcademicChatter #PublishOrPerish #Elsevier #Springer #MDPI #Wiley #Frontiers #PhDAdvice #PhDChat #SciComm


The strain on scientific publishing
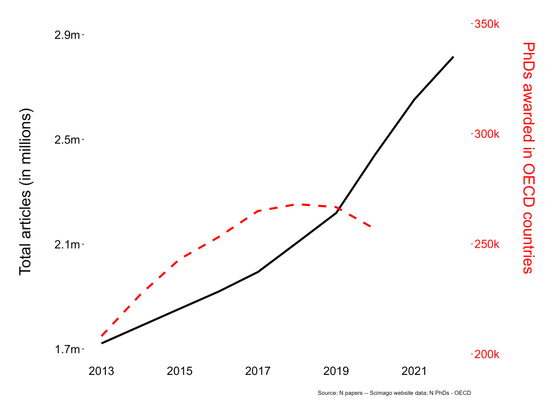
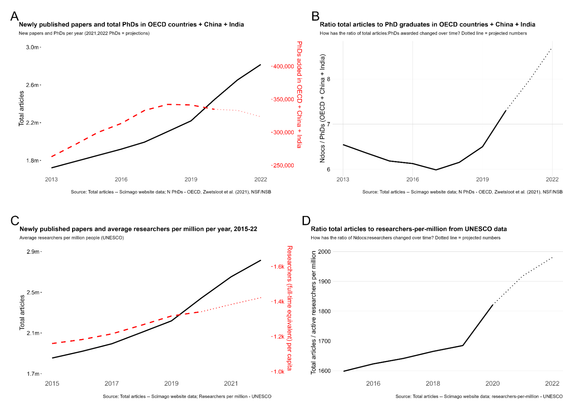
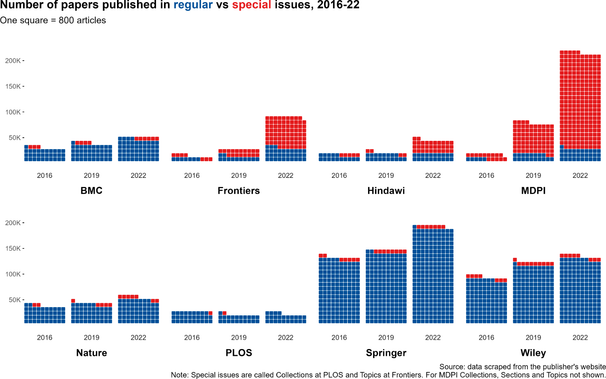
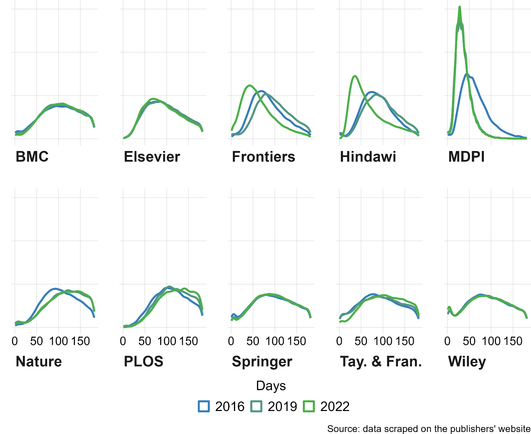
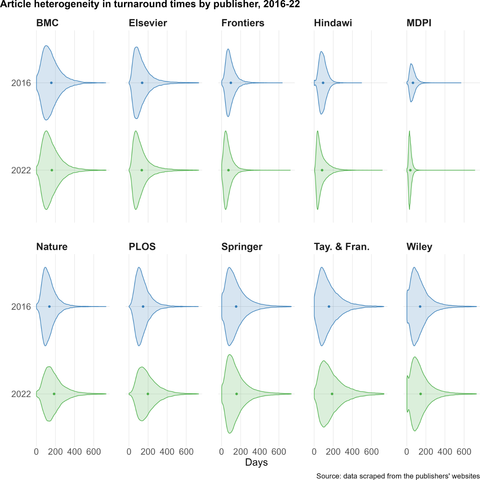
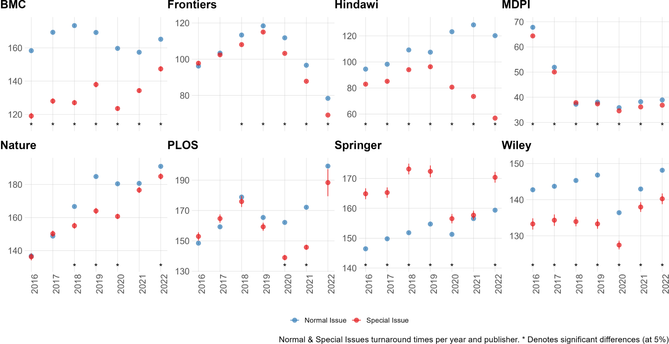
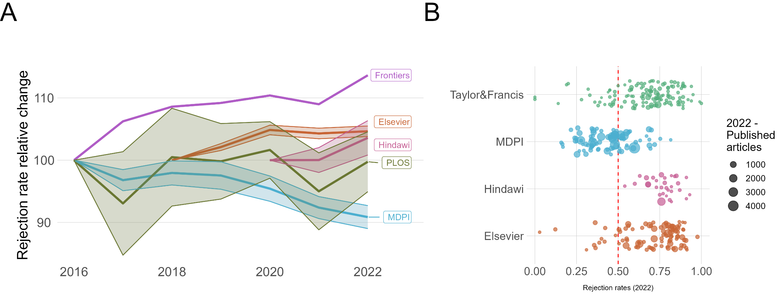
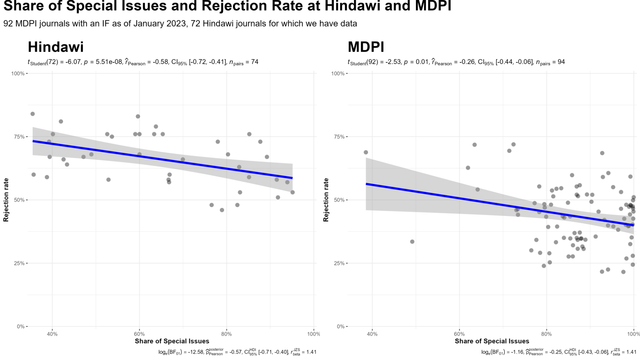
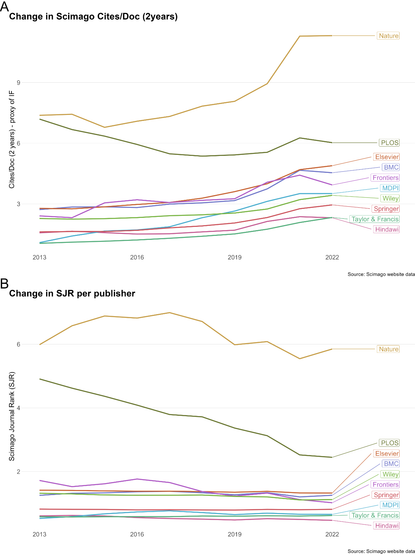
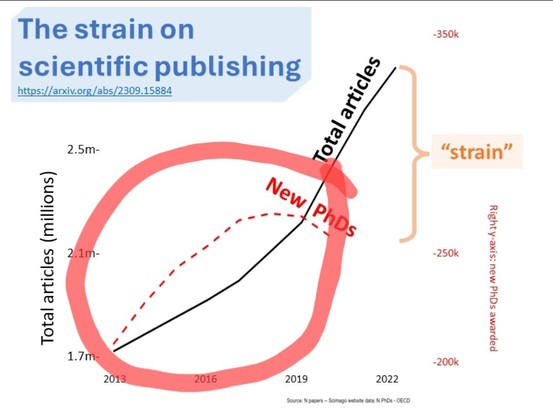
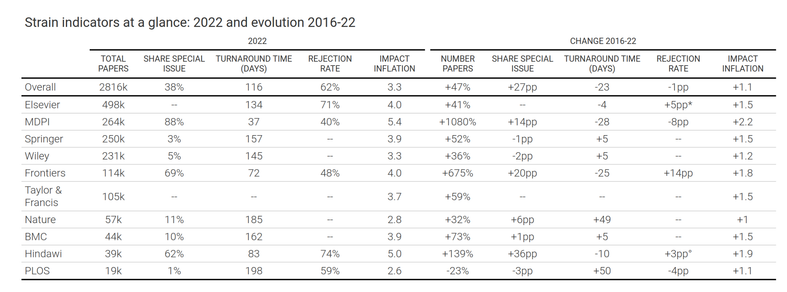
Scientists are increasingly overwhelmed by the volume of articles being published. Total articles indexed in Scopus and Web of Science have grown exponentially in recent years; in 2022 the article total was approximately ~47% higher than in 2016, which has outpaced the limited growth - if any - in the number of practising scientists. Thus, publication workload per scientist (writing, reviewing, editing) has increased dramatically. We define this problem as the strain on scientific publishing. To analyse this strain, we present five data-driven metrics showing publisher growth, processing times, and citation behaviours. We draw these data from web scrapes, requests for data from publishers, and material that is freely available through publisher websites. Our findings are based on millions of papers produced by leading academic publishers. We find specific groups have disproportionately grown in their articles published per year, contributing to this strain. Some publishers enabled this growth by adopting a strategy of hosting special issues, which publish articles with reduced turnaround times. Given pressures on researchers to publish or perish to be competitive for funding applications, this strain was likely amplified by these offers to publish more articles. We also observed widespread year-over-year inflation of journal impact factors coinciding with this strain, which risks confusing quality signals. Such exponential growth cannot be sustained. The metrics we define here should enable this evolving conversation to reach actionable solutions to address the strain on scientific publishing.