SubQ: Sub-quadratic LLM built for 12M-token reasoning
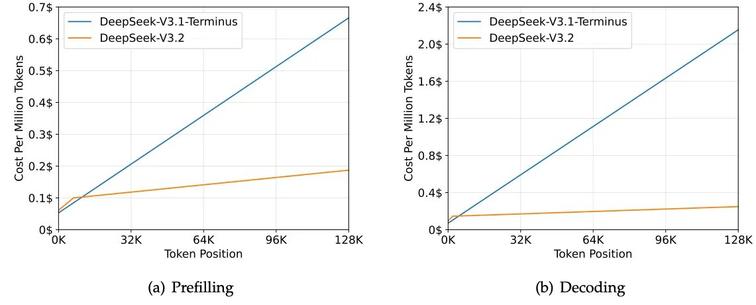
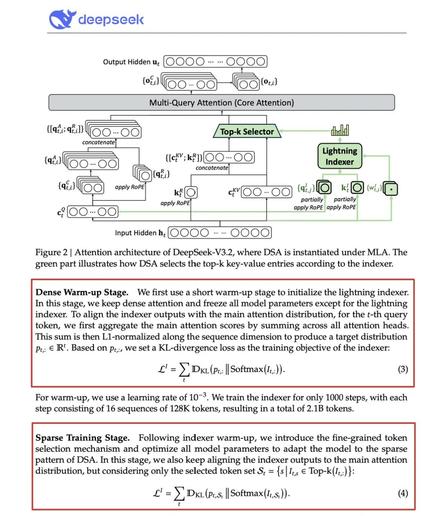
SubQ는 12백만 토큰의 긴 문맥 추론을 지원하는 최초의 완전한 서브쿼드러틱(sub-quadratic) LLM으로, 전체 코드 저장소, 긴 이력, 지속 상태를 품질 저하 없이 처리할 수 있다. 기존 트랜스포머의 O(n²) 복잡도를 O(n)으로 줄인 희소 어텐션 아키텍처를 적용해 계산량을 1,000배 이상 절감하며, 긴 문맥 기반 소프트웨어 엔지니어링 작업에서 우수한 성능을 보인다. 개발자와 기업을 위한 API와 코딩 에이전트용 레이어를 제공하며, OpenAI 호환 엔드포인트와 통합 가능하다. 이는 LLM의 긴 문맥 처리 한계를 근본적으로 확장하는 혁신적 아키텍처다.
#llm #longcontext #transformer #sparseattention #aiarchitecture