David Duvenaud (@DavidDuvenaud)
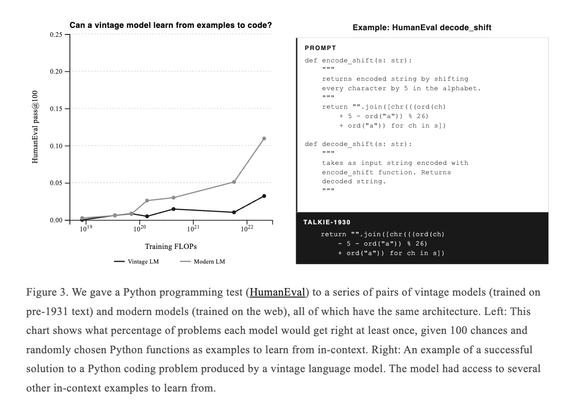
구형 모델들이 인컨텍스트 러닝만으로는 Python의 아주 기본적인 작업을 간신히 수행할 수 있다고 언급했다. 오래된 AI 모델의 제한된 코딩 능력을 보여주는 기술적 관찰로, 모델 성능 차이를 시사한다.
David Duvenaud (@DavidDuvenaud)
구형 모델들이 인컨텍스트 러닝만으로는 Python의 아주 기본적인 작업을 간신히 수행할 수 있다고 언급했다. 오래된 AI 모델의 제한된 코딩 능력을 보여주는 기술적 관찰로, 모델 성능 차이를 시사한다.
fly51fly (@fly51fly)
반복 데이터 분석을 더 저렴하게 수행할 수 있도록 사전식 인코딩과 인컨텍스트 러닝을 활용한 무손실 프롬프트 압축 기법을 제안합니다. LLM 분석 비용을 줄이는 실용적인 개발 기법입니다.
https://x.com/fly51fly/status/2044892575375794314
#promptcompression #llm #incontextlearning #research #costoptimization
Awni Hannun (@awnihannun)
Transformer 아키텍처에 대해 '긴 KV 캐시와 희소 조회(sparse lookup, DSA 유사)'가 균형적이라는 기술적 의견을 제시하는 트윗입니다. 토큰에 따라 메모리가 선형적으로 늘고(장기 기억·인컨텍스트 학습에 유리), 계산량은(거의) 선형에 가깝다고 설명합니다. 아키텍처 최적화 제안입니다.

A long KV cache with sparse lookup (kind of like DSA) strikes me as the right balance for a Transformer. - Memory is not fixed but scales linearly with tokens (which is good for remembering things + in-context learning) - Compute is (almost) linear rather than quadratic
BOOTOSHI (@KingBootoshi)
코딩 에이전트 관련 문제는 모델에게 충분히 정보를 제공하는 것으로 대부분 해결될 수 있으며, 많은 사람이 모델의 인컨텍스트 러닝(in-context learning) 능력을 과소평가한다고 지적합니다. 작성자는 전역 'claude.md'(~/.claude)에 코드베이스 전반에 적용할 일반 패턴을 기록해 두고 사용한다고 설명합니다.

every single problem i see people have with coding agents can be solved by informing them people sleep on the in-context learning these models are capable of in the global claude MD at ~/.claude that's where i write general patterns that apply to every single codebase/languages
fly51fly (@fly51fly)
논문 'Scaling In-Context Online Learning Capability of LLMs via Cross-Episode Meta-RL'이 arXiv(2026)에 공개되었습니다. Boston University와 LinkedIn 소속 연구진(X Lin, S Zhu, Y Chen, M Chen 등)이 크로스-에피소드 메타-RL 기법으로 LLM의 인컨텍스트 온라인 학습 능력을 확장하는 방법을 제안하여 실시간 적응·학습 성능 개선 가능성을 보였습니다. arXiv 링크 포함.
zai-org giới thiệu **SCAIL** - mô hình AI tạo hoạt ảnh nhân vật chất lượng chuyên nghiệp bằng học tập ngữ cảnh. SCAIL tích hợp biểu diễn tư thế 3D-Consistent và kỹ thuật "full-context pose injection" để học chuyển động chi tiết, chính xác. Công nghệ này giúp tối ưu hóa quan hệ không gian-thời gian trong video. Khám phá tại blog/Huggingface/Github.
#AIAnimation #Technology #MôHìnhAI #HoạtNhânNhânVật #3DAnimation #InContextLearning #TríTuệNhiệtNhânTạo
In-context learning has been consistently shown to exceed hand-crafted neural learning algorithms across the board.
But it's limited by the length of the context. Even with neural architectures allowing context to grow to infinity, these come with high costs and scaling problems.
Is there a way to incorporate new knowledge learned in-context back into neural network weights?
Of course there is!
Let's imagine we have a lot of data, sequences of instructions and outputs where in-context learning happens.
From this data we can produce a dataset of synthetic data which presents the new knowledge learned. We can continually train the model with this dataset.
Of course this is super slow and inconvenient. But as a result we'll get a dataset with in-context learning happening, and old model weights against new model weights.
We can use this data to train a neural programmer model directly!
That model would take in the context as such, and if in-context learning has happened in those interactions, it can predict the changes to the neural network weights which would happen if the long and heavy synthetic data pipeline had been run.
Instead of the heavy pipeline, we can just use the neural programmer model to directly update the large model weights based on the in-context learning it experienced, to crystallize the learnings into its long-term memory, not unlike what hippocampus does in the human brain.
KumoRFM: A Foundation Model for In-Context Learning on Relational Data
https://kumo.ai/company/news/kumo-relational-foundation-model/
#HackerNews #KumoRFM #InContextLearning #RelationalData #FoundationModel #AIResearch

Foundation Models have completely taken over unstructured data domains like natural language and images, delivering significant advances in performance across tasks with little to no task-specific training. Yet structured and semi-structured relational data, which represent some of the most valuable information assets, largely miss out on this AI wave. Here, we present KumoRFM, a Relational Foundation Model (RFM) capable of making accurate predictions over relational databases across a wide range of predictive tasks without requiring data or task-specific training.

MIT researchers have explained how large language models like GPT-3 are able to learn new tasks without updating their parameters, despite not being trained to perform those tasks. They found that these large language models write smaller linear models inside their hidden layers, which the large models can train to complete a new task using simple learning algorithms.
Through scaling #DeepNeuralNetworks we have found in two different domains, #ReinforcementLearning and #LanguageModels, that these models learn to learn (#MetaLearning).
They spontaneously learn internal models with memory and learning capability which are able to exhibit #InContextLearning much faster and much more effectively than any of our standard #backpropagation based deep neural networks can.
These rather alien #LearningModels embedded inside the deep learning models are emulated by #neuron layers, but aren't necessarily deep learning models themselves.
I believe it is possible to extract these internal models which have learned to learn, out of the scaled up #DeepLearning #substrate they run on, and run them natively and directly on #hardware.
This allows those much more efficient learning models to be used either as #LearningAgents themselves, or as a further substrate for further meta-learning.
I have an #embodiment #research on-going but with a related goal and focus specifically in extracting (or distilling) the models out of the meta-models here:
https://github.com/keskival/embodied-emulated-personas
It is of course an open research problem how to do this, but I have a lot of ideas!
If you're inspired by this, or if you think the same, let's chat!

A project space for Embodied Emulated Personas - Embodied neural networks trained by LLM chatbot teachers - GitHub - keskival/embodied-emulated-personas: A project space for Embodied Emulated Perso...