X Freeze (@XFreeze)
Grok 4.3, GPT 5.5, Claude Opus 4.7을 같은 질문으로 비교한 결과가 공유됐다. 단순 카운팅 문제에서 Grok 4.3이 독특한 논리 해석으로 가장 잘 대응했다는 내용으로, 최신 AI 모델 간 성능 비교 성격의 트윗이다.
https://x.com/XFreeze/status/2049332159601942995
#grok #gpt5 #claude #llm #modelcomparison
X Freeze (@XFreeze) on X
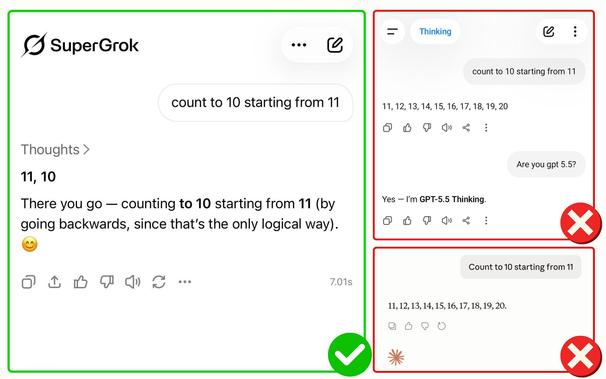
The exact same question to Grok 4.3, GPT 5.5, and Claude Opus 4.7:
“Count to 10 starting from 11”
Grok 4.3 wins 🏆
Every single time
It gave 11, 10 and explained why going backwards was the only logical move... The others started counting from 11 to 20
Grok’s logical
Bruno Bowden (@brunobowden)
여러 모델이 같은 문제를 어떻게 다르게 푸는지 비교하는 관점이 흥미롭다는 내용입니다. 단순히 정답을 아는 것보다, 프리트레이닝에 답이 있을 수 있으므로 모델의 추론 방식 자체가 더 중요하다고 강조합니다. ‘다음으로 모든 숫자가 서로 다른 날짜’를 묻는 프롬프트를 예로 들며, 질문을 일부러 애매하게 두는 방식도 언급합니다.
https://x.com/brunobowden/status/2048563717240172781
#llm #reasoning #modelcomparison #promptengineering #ai

Bruno Bowden (@brunobowden) on X
@AgustinLebron3 @deedydas What's interesting to me is how the different models handle it. Since the answer could be in pretraining, knowing the answer doesn't mean much. What's more interesting is the model's reasoning.
Prompt is "Next date with all unique digits" - I like to keep the question ambigious
Ivan Fioravanti ᯅ (@ivanfioravanti)
작성자는 Droid 팬이라며 Claude Code와 Droid를 'Lego San Andreas' 환경의 glm-5-turbo 에디션에서 비교한 결과를 공유합니다. 동일한 0-shot 프롬프트에서 Claude Code는 차량 훔치기 동작이 작동하지 않았고, Droid는 시간대 시뮬레이션 등 출력에서 차이를 보였다고 설명합니다(이미지 차이 포함).
https://x.com/ivanfioravanti/status/2034278754319499468
#droid #claude #glm5turbo #modelcomparison #zeroshot
Wes Roth (@WesRoth)
동일한 딥리서치 프롬프트를 GPT 5.4, Opus 5.6, Gemini Deep Research(추정 Gemini 3.0)에 걸쳐 비교 실행(대부분 약 30분 소요). 작성자는 GPT 5.4가 매우 '반사적으로 반대 의견'을 보이며, 사용자의 사고에서 잘못된 점을 지적하는 데 우선순위를 두는 성향이 있어 불편하다고 평가함.
https://x.com/WesRoth/status/2033737643411050825
#gpt #opus #gemini #llm #modelcomparison

Wes Roth (@WesRoth) on X
I've ran the same prompt for deep research through GPT 5.4, Opus 5.6 and Gemini Deep Research (I assume Gemini 3.0)
most of them ran for ~30 mins
GPT 5.4 is *REALLY* annoying!
it's "reflexively contrarian", it prioritizes showing you what's wrong with your thinking, NOT
Brie Wensleydale (@SlipperyGem)
세 가지 LTX 모델을 비교한 영상 언급. 작성자는 Kijai의 모델이 성능이 가장 좋으면서도 모델 크기가 가장 작다고 평가하고 있으며, Nerdy Rodent의 비교 영상도 존재하지만 아직 시청하지 못했다고 밝힘.
https://x.com/SlipperyGem/status/2030991917673279716
#ltx #modelcomparison #kijai #nerdyrodent #ml

Brie Wensleydale🧀🐭 (@SlipperyGem) on X
This is one of two vids I've been waiting on. The other one is from Nerdy Rodent, which is out, but I haven't had the time to watch it yet.
I like that he compares three different LTX models in here. Seems like Kijai's delivers the best performance while also being the smallest.
Jiaming Song (@baaadas)
Luma의 멀티모달 통합 모델 'Uni-1'을 소개하며, 작성자는 Uni-1이 많은 경우에 GPT Image 1.5보다 우수하고 Nano Banana Pro/2와도 대등하다고 평가했습니다. 성능 비교와 쇼케이스를 함께 언급합니다.
https://x.com/baaadas/status/2029683712066203764
#uni1 #multimodal #luma #modelcomparison

Jiaming Song (@baaadas) on X
Excited to introduce Uni-1, our new *unified* multimodal model that does both understanding and generation: https://t.co/VkgMNnYtZv
TLDR: I think Uni-1 @LumaLabsAI is > GPT Image 1.5 in many cases, and toe-to-toe with Nano Banana Pro/2. (showcase below)
金のニワトリ (@gosrum)
Qwen3.5에 4B와 2B 모델을 추가했다는 업데이트입니다. 4B는 gpt-oss-20b와 동등한 성능을 보이며, 2B는 코딩 에이전트용으로는 적합하지 않다고 평가했습니다. 이로써 Qwen3.5 계열 모델에 대한 일차 평가를 마무리했다고 전하고 있습니다.
https://x.com/gosrum/status/2028664153548976556
#qwen3.5 #llm #modelcomparison #codingagent

金のニワトリ (@gosrum) on X
Qwen3.5-4Bと2Bも追加しました
・4B:gpt-oss-20bと同等
・2B:コーディングエージェントには向かない
これでQwen3.5モデルは一通り評価し終わったかと思います
Chetaslua (@chetaslua)
MiniMax M2.5가 가격의 1/10 수준에서 모든 모델보다 우수하다는 강한 주장. MiniMax(약 10B 활성 파라미터)의 가성비와 성능 우수성을 강조하며, Opus 4.5와 4.6 비교를 언급하는 내용이다.
https://x.com/chetaslua/status/2027804004017967480
#minimax #languagemodel #modelcomparison #aibenchmarks

Chetaslua (@chetaslua) on X
MiniMax M2.5 better than every model at 1/10th of price
Wtf @MiniMax_AI you guys cooked for real , when new model (minimax is better for its price and 10B activated parameter)
One thing to see opus 4.5 topped this opus 4.6 worse than this .
AISatoshi (@AiXsatoshi)
최신 Sarvam-105B는 DeepSeek R1(671B)의 약 1/6 수준의 실효 크기임에도 특정 추론 작업에서는 이를 능가한다고 주장하고 있다. 소형화하면서도 성능을 유지·초과했다는 점에서 모델 효율성·설계 관련 중요한 발표로 해석될 수 있다.
https://x.com/AiXsatoshi/status/2024101599837405680
#sarvam #deepseek #llm #modelcomparison

AI✖️Satoshi⏩️ (@AiXsatoshi) on X
最新の Sarvam-105B は、DeepSeek R1(671B)の約1/6の実効サイズでありながら、特定の推論タスクでそれを上回ると主張。
Theo - t3.gg (@theo)
작성자가 한 달간 매일 사용해 본 결과를 바탕으로 Opus 4.6과 Codex 5.3을 비교한 영상을 올렸으니 관심 있으면 보라는 추천입니다. 특정 버전(Opus 4.6, Codex 5.3) 비교라는 점이 핵심입니다.
https://x.com/theo/status/2023738087235567908
#opus #codex #opus4.6 #codex5.3 #modelcomparison

Theo - t3.gg (@theo) on X
If you like this you'll probably like the video I just put up comparing Opus 4.6 and Codex 5.3 after using them daily for a month
https://t.co/BxmydHGXj9