3 mô hình lập trình ~60GB: GLM 4.7 Flash, GPT OSS 120B, Qwen3 Coder 30B. Qwen3 xuất hiện từ 7/2025, GLM mới trải nghiệm 1 tuần. Bạn đã sử dụng các mô hình nào? Chia sẻ ưu/nhược điểm. #AI #LậpTrình #GLM #GPT #Qwen3 #ModelComparison #CodingAI
https://www.reddit.com/r/LocalLLaMA/comments/1qn3evg/60gb_models_on_coding_glm_47_flash_vs_gpt_oss/
Xeophon (@xeophon)
작성자는 시각적 그래디언트 품질이 @OpenAIDevs의 gpt-5.2-codex xhigh에서 가장 좋았다고 평가하며, 청구서(invoice) 결과물은 별로였다고 언급합니다. 이어 모델 성능 순위를 Codex > M2.1 > GLM > Claude > Gemini로 제시해 최신 모델 비교 의견을 공유합니다.
https://x.com/xeophon/status/2005620484537295137
#gpt5.2 #codex #modelcomparison #openai

Xeophon (@xeophon) on X
@AmpCode The best-looking gradient slop came from
@OpenAIDevs gpt-5.2-codex xhigh. The invoice, OTOH, looks mediocre as well.
Verdict: Codex > M2.1 > GLM > Claude > Gemini
Joss López (@jossslopez)
배경 자동화를 FLORA 내부에서 구현한 작업 설명입니다. 사용 스택: ChatGPT 5.2가 6개의 프롬프트를 생성해 입력을 만들고, Flux 2 Pro 대 Seedream 4.5로 시각 비교를 진행하며 Kling 2.5 대 Kling o1로 렌더/스타일 대결을 수행합니다. 배경 생성 파이프라인 자동화와 여러 모델/버전 비교 실험을 보여줍니다.
https://x.com/jossslopez/status/2004858293744009363
#automation #promptengineering #chatgpt #modelcomparison
Emily (@IamEmily2050)
여러 대형 언어모델(Grok 4, Gemini 3 Pro, Opus 4.5, GPT 5.2 pro)에 '가장 아름다운 여성 얼굴'을 상세히 묘사하라는 동일 질문을 던지고, 각 모델의 응답을 NotebookLM으로 통합해 보고서(예: "The Artist's Guide to Facial Aesthetics")를 만든 사례를 공유한 트윗입니다. 모델 비교와 노트북형 LLM 워크플로우 활용을 보여줍니다.
https://x.com/IamEmily2050/status/2004532836846780534
#llm #modelcomparison #notebooklm #prompting

Emily (@IamEmily2050) on X
I asked Grok 4 + Gemini 3 Pro + Opus 4.5 + GPT 5.2 pro one question (How do you describe the most beautiful human woman face in details?)
Then took the answers to NotebookLM and asked to create a report.
The Artist's Guide to Facial Aesthetics: A Manual on Structure, Harmony,
#statstab #393 Statistically Efficient Ways to Quantify Added Predictive Value of New Measurements [actual post]
Thoughts: #392 has the comments, but this is where the magic happens.
#modelselection #modelcomparison #variance #effectsize #tutorial
https://www.fharrell.com/post/addvalue/

Statistically Efficient Ways to Quantify Added Predictive Value of New Measurements – Statistical Thinking
Researchers have used contorted, inefficient, and arbitrary analyses to demonstrated added value in biomarkers, genes, and new lab measurements. Traditional statistical measures have always been up to the task, and are more powerful and more flexible. It’s time to revisit them, and to add a few slight twists to make them more helpful.
#statstab #359 A Pragmatic Approach to Statistical Testing and Estimation (PASTE)
Thought: A (basic) guide to some alternatives to p-values: bayesian posterior intervals, Bayes Factors, and AIC.
#NHST #pvalues #TOST #BayesFactor #AIC #modelcomparison
https://doi.org/10.1016/j.hpe.2017.12.009
A Pragmatic Approach to Statistical Testing and Estimation (PASTE)
The p-value has dominated research in education and related fields and a statistically non-significant p-value is quite commonly interpreted as ‘confirming’ the null hypothesis (H0) of ‘equivalence’. This is unfortunate, because p-values are not fit for that purpose. This paper discusses three alternatives to the traditional p-value that unfortunately have remained underused but can provide evidence in favor of ‘equivalence’ relative to ‘non-equivalence’: two one-sided tests (TOST) equivalence testing, Bayesian hypothesis testing, and information criteria. TOST equivalence testing and p-values both rely on concepts of statistical significance testing and can both be done with confidence intervals, but treat H0 and the alternative hypothesis (H1) differently. Bayesian hypothesis testing and the Bayesian credible interval aka posterior interval provide Bayesian alternatives to traditional p-values, TOST equivalence testing, and confidence intervals. However, under conditions outlined in this paper, confidence intervals and posterior intervals may yield very similar interval estimates. Moreover, Bayesian hypothesis testing and information criteria provide fairly easy to use alternatives to statistical significance testing when multiple competing models can be compared. Based on these considerations, this paper outlines a pragmatic approach to statistical testing and estimation (PASTE) for research in education and related fields. In a nutshell, PASTE states that all of the alternatives to p-values discussed in this paper are better than p-values, that confidence intervals and posterior intervals may both provide useful interval estimates, and that Bayesian hypothesis testing and information criteria should be used when the comparison of multiple models is concerned.

The limited epistemic value of ‘variation analysis’
While appeal to R squared is a common rhetorical device, it is a very tenuous connection to any plausible explanatory virtues for many reasons. Either it is meant to be merely a measure of predicta…
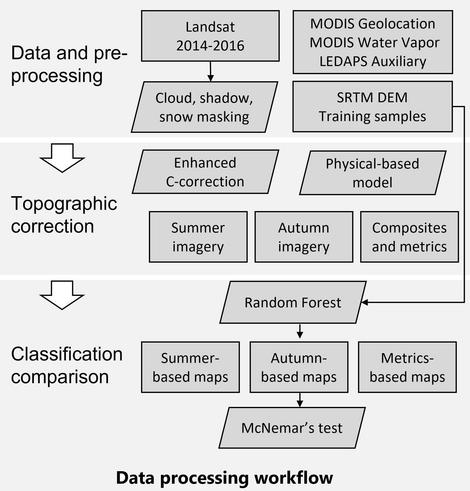
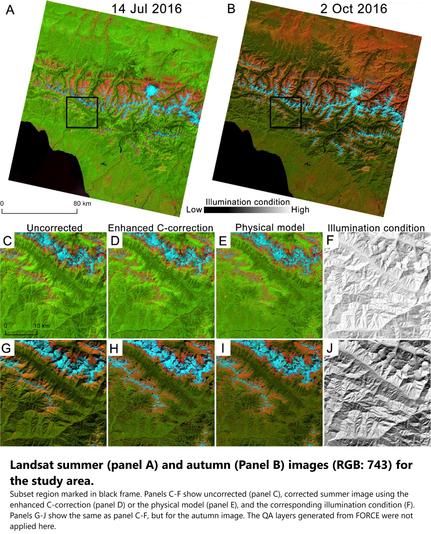
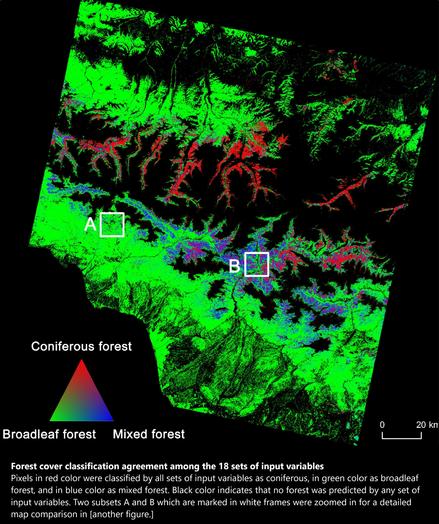
Integrated Topographic Corrections Improve Forest Mapping Using Landsat Imagery
--
https://doi.org/10.1016/j.jag.2022.102716 <-- shared 2022 paper
--
“HIGHLIGHTS:
• [They] evaluated the impacts of topographic correction on forest mapping in the mountains.
• The enhanced C-correction and the physical model reduced topographic effects.
• The corrected Landsat imagery time series resulted in higher accuracy.
• Terrain information improved classification but not as much as topographic correction.
• [They] recommend using topographic correction for forest cover mapping..."
#GIS #spatial #AtmosphericCorrection #IlluminationCondition #LandCover #ModelComparison #TimeSeries #TopographicCorrection #remotesensing #comparasion #topographic #correction #NDVI #forest #vegetation #model #modeling #spatialanalyis #accuracy #forestcover #Russia #Georgia #CaucasusMountains #spatiotemporal #landsat #elevation #DEM
Integrated topographic corrections improve forest mapping using Landsat imagery
In mountainous environments, topography strongly affects the reflectance due to illumination effects and cast shadows, which introduce errors in land …
#statstab #196 JASP Bayesian ANOVA
Thoughts: @JASPStats is used by researchers to "add some bayes factors" to their results. But, do you know what those actually reflect? Here is what their team says:
#bayes #bayesfactors #anova #modelcomparison
https://static.jasp-stats.org/about-bayesian-anova.html
JASP - A Fresh Way to do Statistics
#statstab #174 The Principle of Predictive Irrelevance
Thoughts: "when two competing models predict a data set equally well, that data set cannot be used to discriminate the models and the data set is evidentially irrelevant"
#modelcomparison #inference
https://www.bayesianspectacles.org/the-principle-of-predictive-irrelevance-or-why-intervals-should-not-be-used-for-model-comparison-featuring-a-point-null-hypothesis/

The Principle of Predictive Irrelevance, or Why Intervals Should Not be Used for Model Comparison Featuring a Point Null Hypothesis
This post summarizes Wagenmakers, E.-J., Lee, M. D., Rouder, J. N., & Morey, R. D. (2019). The principle of predictive irrelevance, or why intervals should not be used for model comparison feat…