Công cụ dòng lệnh (CLI) mã nguồn mở hỗ trợ tinh chỉnh (SFT, RL, DPO, ORPO, PPO), suy luận và tương thích MPS. Dễ dàng huấn luyện mô hình trên Mac và NVIDIA. Kiểm tra mô hình cục bộ sau huấn luyện.
👉 pip install aitraining
⭐ trên GitHub: github.com/monostate/aitraining
#AI #ML #opensource #LLM #aitraining #trituenhantao #machinlearning #manguonmo
For those asking versus an RTX 4000 vs RTX 5000 on a laptop, wait if you can.
Unless you have a very good offer on an old RTX 4000 Mobile series, you may wait for RTX 5000 with their better Ray Tracing and DLSS4 performance.
#NVIDIA #RTX #Laptop #Laptops #RTX5070 #RTX5070Ti #RTX5080 #RTX5090 #RayTracing #PathTracing #DLSS #DLSS4 #GeForce #Hardware #PCHardware #LaptopHardware #Videogames #Gaming #Games #AI #ML #MachinLearning #LM #LLM #LargeLanguageModel
EUROCONTROL Performance Review Commission's Data Challenge is out!
https://ansperformance.eu/study/data-challenge/
With info on 369013 European flights from EUROCONTROL and relevant #adsb trajectories from @openskynetwork you can compete and build an open #machinlearning model to predict a flight's takeoff weight (good input for fuel burnt and gas emissions estimations).
Excitement started building yesterday around rumors that Llama 3.1 (open source) would outperform proprietary models like GPT-4o. Now we have the public release, so people can judge for themselves. 1/2 #machinlearning #MLSky
Meta announcement: ai.meta.com/blog/meta-ll...
@look997 to przemyślenie brzmi bardziej jak emocjonalne zaburzenie lub dewiacja na punkcie całkiem ludzkich relacji. Lepiej pograć w simsy, tamagotchi czy pokemony.
Zrozumienie #machinlearning czyli #nauczaniemaszynowe to klucz do tego aby zrozumieć jak działa i skąd otrzymywany jest wynik prompt w popularnych teraz modelach dopełniania czy czatowania - w tym nie ma "czarnej magii" i proszę nie personifikować i przypisywać cech stricte "ludzkich" technologii, która zawiła i nie do końca już zrozumiała w działaniu, której efekt jest tak wspaniały, to jednak ten efekt nie został stworzony przy użyciu "czarnej magii"...
Przypomina mi się słynny wykład Jamesa Veitch'a apropos spamu jako przykład podobnej relacji:
https://www.youtube.com/watch?v=davHBmGQFCQ
Polecam więcej relacji z tymi realnymi, ludzkimi przyjaciółkami - może trafi się taka, co by chętnie posłuchała o #ai, hm? Wtedy będzie to już ludzka i nie zmyślona relacja 😉

This Is What Happens When You Reply To A Spam Email | James Veitch | TED.com
If you’re at #CropIB, let’s meet! 🤗Our team team is in Amsterdam for Crop Innovation in a Changing Environment 🌱Meet us at the conference and get to know our cutting-edge #predictivebreeding technology👉 https://bit.ly/43AZnSL
#xSeedScore #machinlearning #climatechange
#xSeedScore #machinlearning #climatechange

🔎What's in a layer?🌹🕵🏻♀️
Representations are vectors
If only they were words...
Finding:
Any layer can be mapped well to another linearly
Simple, efficient & interpretable
& improves early exit
https://arxiv.org/abs/2303.09435v1
Story and 🧵
#nlproc #deepRead #MachinLearning
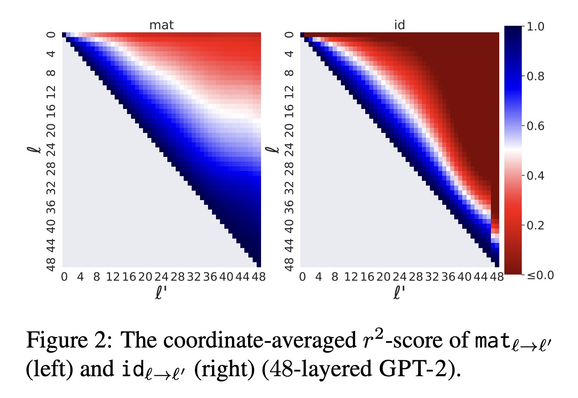

Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
“Technologies like machine learning will make it possible to think about what will be in 10 years.
Patrizia Ricca, Scientific Product Manager for Computomics’ predictive plant breeding technology, gives comprehensive insight into the tool that enables plant breeders to develop crop varieties for future climates ☀️ 🌱 Listen to Patrizia’s take on the future of plant breeding! 👉 https://buff.ly/3kjMzhb
#podcast #machinlearning #predictivebreeding #geneticgain #climatechange

Runway's got a new quick training tool for simple models:
We want to pretrain🤞
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc #MachinLearning #NLP #ML #modelRecyclying #collaborativeAI #scientivism #pretrain