Back in the days of 2021
there was a lovely evaluation paper:
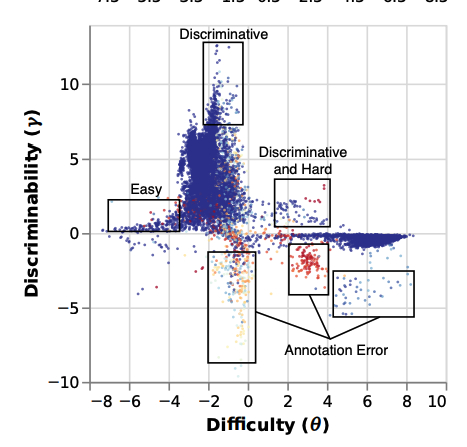
Automatically identifying label errors
Improving score's reliability
Finding example's difficulty
Active Learning
https://aclanthology.org/2021.acl-long.346/
@par @hoyle
#machinelearning #evaluation #IRT #LLM #deepRead

Evaluation Examples are not Equally Informative: How should that change NLP Leaderboards?
Pedro Rodriguez, Joe Barrow, Alexander Miserlis Hoyle, John P. Lalor, Robin Jia, Jordan Boyd-Graber. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021.
Did you know:
Evaluating a single model on HELM took
⏱️4K GPU hours or 💸+10K$ in API calls?!
Flash-HELM⚡️can reduce costs by X200!
https://arxiv.org/abs/2308.11696
#deepRead #machinelearning #evaluation #eval #nlproc #NLP #LLM
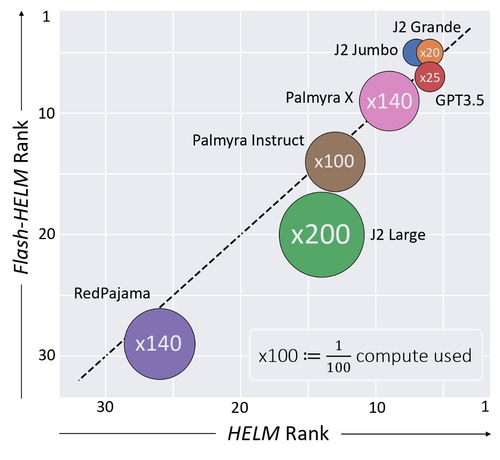

Efficient Benchmarking of Language Models
The increasing versatility of language models (LMs) has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs, extending to thousands of GPU hours per model. However, the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work, we present the problem of Efficient Benchmarking, namely, intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case, we investigate how different benchmark design choices affect the computation-reliability trade-off. We propose to evaluate the reliability of such decisions, by using a new measure -- Decision Impact on Reliability, DIoR for short. We find, for example, that a benchmark leader may change by merely removing a low-ranked model from the benchmark, and observe that a correct benchmark ranking can be obtained by considering only a fraction of the evaluation examples. Based on our findings, we outline a set of concrete recommendations for efficient benchmark design and utilization practices. To take a step further, we use our findings to propose an evaluation algorithm, that, when applied to the HELM benchmark, leads to dramatic cost savings with minimal loss of benchmark reliability, often reducing computation by x100 or more.
The newFormer is introduced,
but what do we really know about it?
@ari and others
imagine a new large-scale architecture &
ask how would you interptret its abilities and behaviours 🧵
https://arxiv.org/abs/2308.00189
#deepRead #NLProc #MachineLearning

Generative Models as a Complex Systems Science: How can we make sense of large language model behavior?
Coaxing out desired behavior from pretrained models, while avoiding
undesirable ones, has redefined NLP and is reshaping how we interact with
computers. What was once a scientific engineering discipline-in which building
blocks are stacked one on top of the other-is arguably already a complex
systems science, in which emergent behaviors are sought out to support
previously unimagined use cases.
Despite the ever increasing number of benchmarks that measure task
performance, we lack explanations of what behaviors language models exhibit
that allow them to complete these tasks in the first place. We argue for a
systematic effort to decompose language model behavior into categories that
explain cross-task performance, to guide mechanistic explanations and help
future-proof analytic research.
@mega Linear transformations can skip over layers, even till the end
We can see 👀 what the network 🧠 thought!
We can stop🛑 generating at early layers!
https://arxiv.org/abs/2303.09435v1
#NLProc #deepRead
Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
🔎What's in a layer?🌹🕵🏻♀️
Representations are vectors
If only they were words...
Finding:
Any layer can be mapped well to another linearly
Simple, efficient & interpretable
& improves early exit
https://arxiv.org/abs/2303.09435v1
Story and 🧵
#nlproc #deepRead #MachinLearning
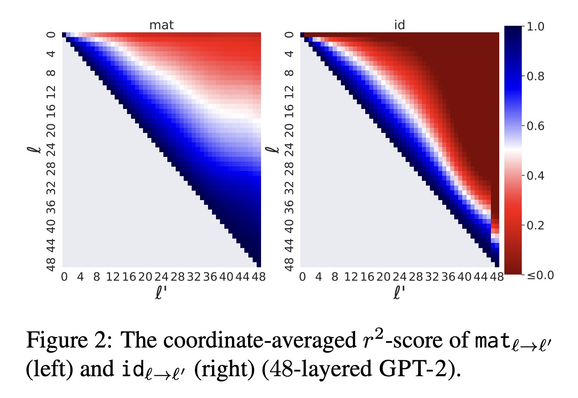
Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
Mindblowing pretraining paradigm
Train the same model to predict the two directions separately
Better results, more parallelization
https://arxiv.org/abs/2303.07295
#deepRead #nlproc #pretraining #machinelearning


Meet in the Middle: A New Pre-training Paradigm
Most language models (LMs) are trained and applied in an autoregressive
left-to-right fashion, assuming that the next token only depends on the
preceding ones. However, this assumption ignores the potential benefits of
using the full sequence information during training, and the possibility of
having context from both sides during inference. In this paper, we propose a
new pre-training paradigm with techniques that jointly improve the training
data efficiency and the capabilities of the LMs in the infilling task. The
first is a training objective that aligns the predictions of a left-to-right LM
with those of a right-to-left LM, trained on the same data but in reverse
order. The second is a bidirectional inference procedure that enables both LMs
to meet in the middle. We show the effectiveness of our pre-training paradigm
with extensive experiments on both programming and natural language models,
outperforming strong baselines.
3 reasons for hallucinations started
only 2 prevailed
Finding how networks behave while hallucinating, they
filter hallucinations (with great success)
https://arxiv.org/abs/2301.07779
#NLProc #neuralEmpty #NLP #deepRead
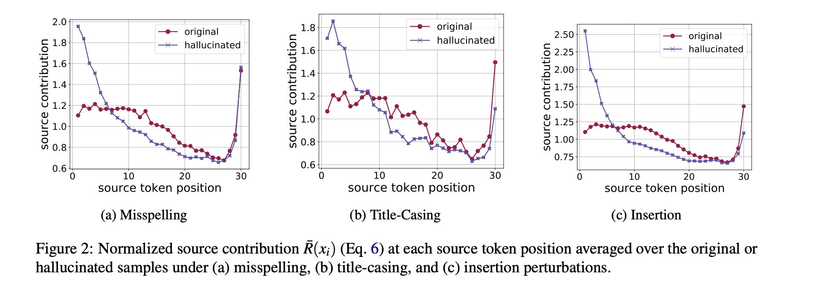
Understanding and Detecting Hallucinations in Neural Machine Translation via Model Introspection
Neural sequence generation models are known to "hallucinate", by producing
outputs that are unrelated to the source text. These hallucinations are
potentially harmful, yet it remains unclear in what conditions they arise and
how to mitigate their impact. In this work, we first identify internal model
symptoms of hallucinations by analyzing the relative token contributions to the
generation in contrastive hallucinated vs. non-hallucinated outputs generated
via source perturbations. We then show that these symptoms are reliable
indicators of natural hallucinations, by using them to design a lightweight
hallucination detector which outperforms both model-free baselines and strong
classifiers based on quality estimation or large pre-trained models on manually
annotated English-Chinese and German-English translation test beds.
I’ve just spent the morning going through the
#mastodon news feed, and I thoroughly enjoyed it. I honestly can’t remember when the last time was I got completely immersed in behind-the-story analysis in this way. Well done,
#mastodon, and thank you.
#mastodonnews #deepread #news #newsanalysisWhat neurons determine agreement in multilingual LLMs?
#deepRead but some answers:
Across languages-2 distinct ways to encode syntax
Share neurons not info
Autoregressive have dedicated synt. neurons (MLM just spread across)
@[email protected] yu xia @[email protected] #conllLivetweet2022