Erica (@ericavaneee)
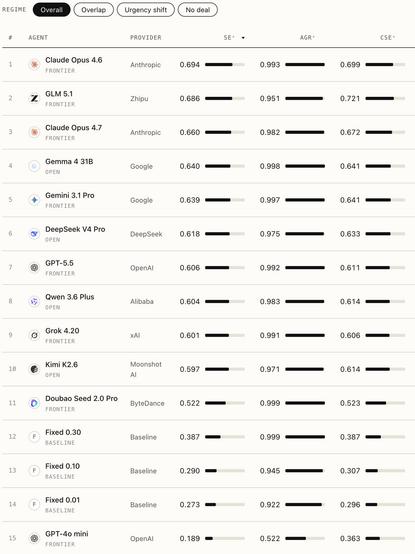
실세계 경제 협상에서 LLM 에이전트를 평가하는 3단계 벤치마크 TERMS-Bench를 공개했다. LLM-as-judge나 결과 기반 루브릭 없이, 환경 자체를 검증자로 사용한다. 프론티어 모델 중 Claude Opus 4.6이 1위, GLM 5.1이 2위로 언급됐다.
Erica (@ericavaneee) on X
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier. 🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2. ✨Surprisingly strong: