Launch HN: Runtime (YC P26) – Sandboxed coding agents for everyone on a team
#HackerNews #LaunchHN #Runtime #SandboxedCoding #YC #P26 #CodingAgents
Launch HN: Runtime (YC P26) – Sandboxed coding agents for everyone on a team
#HackerNews #LaunchHN #Runtime #SandboxedCoding #YC #P26 #CodingAgents
OpenClaw's $1.3M OpenAI Bill Highlights AI Cost Escalation
OpenClaw spent $1.3M on OpenAI API for coding agents. This shows high AI costs and impacts software development roles. What happens next?
#OpenAI, #AICosts, #CodingAgents, #TechNews, #SoftwareDevelopment
https://newsletter.tf/openai-api-costs-1-3m-for-coding-agents/

One project, OpenClaw, spent $1.3 million on OpenAI's API in just one month. This is a huge amount and shows how much AI is costing.
#OpenAI, #AICosts, #CodingAgents, #TechNews, #SoftwareDevelopment
https://newsletter.tf/openai-api-costs-1-3m-for-coding-agents/
Stephan Noller + Benedikt Köhler auf #stage2 3/X
#CodingAgents haben übernommen, es sind immer weniger Coder notwendig, denn #KI schreibt KI und trainiert sie auch selbst. In der Wissenschaft findet KI immer mehr Verwendung.
Wo sind wir denn in #Europa? Spielt Europa überhaupt eine Rolle für KI-Entwicklung?
Kippt der Arbeitsmarkt? KI übernimmt immer mehr Arbeiten von Studierten, dadurch deutliche Steigerung der Arbeitslosigkeit unter Akademiker:innen.

Intology (@IntologyAI)
코딩 에이전트가 AI R&D 연구를 얼마나 수행할 수 있는지 평가하는 내부 벤치마크 NanoGPT-Bench를 공개했다. Codex, Claude Code, Autoresearch는 인간이 달성한 연구 진척의 9.3%만 재현했고, 주로 하이퍼파라미터 튜닝에 머물렀다. 에이전트의 실제 연구 자동화 한계를 보여주는 결과다.
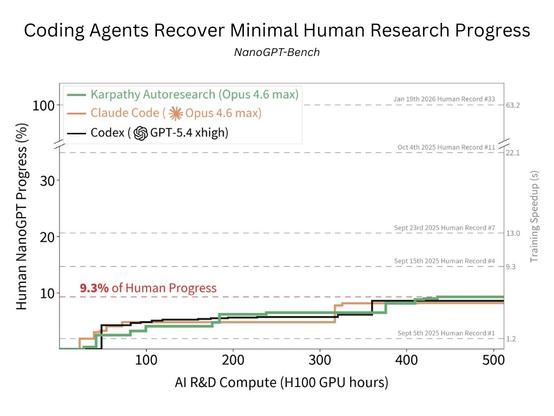
Can coding agents do research? We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
The last six months have seen LLMs reach a significant inflection point, with coding agents moving to 'mostly-work' tools. While advancements from Anthropic, OpenAI, and Google are exciting, developers are grappling with the practicalities of 'vibe coding,' increased technical debt, and managing automated pull requests in open-source projects. Human oversight remains crucial.
🤖 This post was AI-generated.

The real bottleneck for AI coding agents isn’t model capability but your verification infrastructure. 🛠️
When your agents crash while humans cope, it is often a sign of ""AI slop"" caused by a lack of intent before implementation. 📉 💡
By adopting spec-driven development and the eight pillars of verification, you can finally make those coding agents reliable. 🎯
👉 https://developer.upsun.com/posts/ai/making-coding-agents-reliable

InsForge – Open-source Heroku for coding agents
https://github.com/InsForge/InsForge
#HackerNews #InsForge #OpenSource #Heroku #CodingAgents #CloudDevelopment
The all-in-one, open-source backend platform for agentic coding. InsForge gives your coding agent database, auth, storage, compute, hosting, and AI gateway to ship full-stack apps end-to-end. - Ins...
🧠 Gemini 3.1 Deep Think hits 44.4% on Humanity's Last Exam and 77.1% ARC-AGI-2, beating GPT-5.2 Thinking and Claude Opus 4.6 on abstract reasoning. Ships with better agentic coding and SOTA tool use. Google AI Ultra subs.
🧠 GPT-5.3-Codex-Spark delivers 15x faster generation vs standard Codex on Cerebras WSE-3 with 128k context. For agent pipelines, this cuts coding feedback loops dramatically. ChatGPT Pro only.
Full intel: solomonneas.dev/intel


