
Intology (@IntologyAI)
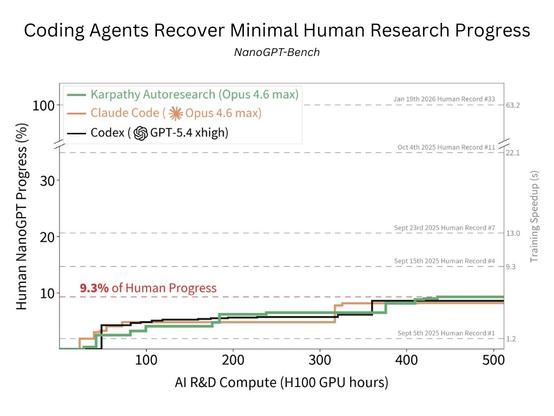
코딩 에이전트가 AI R&D 연구를 얼마나 수행할 수 있는지 평가하는 내부 벤치마크 NanoGPT-Bench를 공개했다. Codex, Claude Code, Autoresearch는 인간이 달성한 연구 진척의 9.3%만 재현했고, 주로 하이퍼파라미터 튜닝에 머물렀다. 에이전트의 실제 연구 자동화 한계를 보여주는 결과다.
Intology (@IntologyAI) on X
Can coding agents do research? We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research






