World Labs (@theworldlabs)
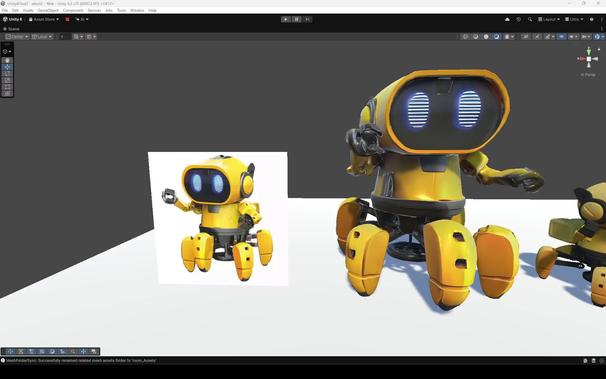
한 장의 이미지를 몇 분 만에 완전한 3D 월드로 변환하는 도구 image-blaster가 소개됐다. World Labs 팀원이 제작했으며, Marble과 Claude, fal을 활용해 3DGS 환경, 메시, 인터랙티브 물리 오브젝트, SFX까지 생성할 수 있다. 이미지 기반 3D 생성과 실시간 상호작용형 월드 제작에 유용한 혁신적 AI 응용 사례다.

World Labs (@theworldlabs) on X
Turn a single image into a fully meshed 3D world in minutes 👀 Built by a World Labs team member, image-blaster combines Marble + Claude skills + @fal to generate 3DGS environments, meshes, interactive physics objects and SFX from one image. learn more + try it yourself ↓