A very honest article that outlines the problems not only with #AI in #science, but with the system of incentives in academic research in general.
The author is a physics graduate who, like many other researchers, has hopped on the AI hype wagon in search for better tools to do his research.
Just to find out that, in spite of many papers claiming that Physics-Informed Neural Networks (PINNs) could be successfully used to solve partial differential equations (PDEs), their results where actually way more underwhelming than they claimed to be, and almost as good as coin tosses when presented with PDEs outside of their carefully cherrypicked training set.
Unlike traditional numeric methods to solve differential equations (which usually operate on a tensor of points and estimate the values at each of those points), a PINN provides an analytical solution and puts the equations into its loss function.
But, for real-world problems, PINNs seem to actually perform worse than the current (non-AI) numeric estimates. The problem is that this is not what emerges from the papers on this topic - the original PINN paper has a whopping 14,000 citations, making it the most cited numerical methods paper of the 21st century.
The underlying issues don’t come to the surface if, in academia like in many other industries, there are no incentives for spotting those issues:
Survivorship bias: Researchers rarely write about their studies that didn’t yield statistically relevant results. Publishers are also usually incentivised to publish studies about new stuff that got discovered rather than studies that explored dead ends. And scientific journalists usually get more clicks if they write articles with titles such as “The upcoming AI revolution in physics“ rather than “This guy tried to solve Navier-Stokes equations with AI, and the results weren’t any better than the methods that have been around for the past four decades“. If only 10% of the studies that tested a certain tool in a certain field yielded some results, and the other 90% didn’t, but only that 10% gets published, then people may start to believe that that tool is much more effective than it actually is. This is also a problem in medical studies, not only in AI: if researchers fail to publish negative results, it can cause medical practitioners and the general public to overestimate the effectiveness of a certain medical treatment. For the sake of science, we should also start publishing papers that seem to lead to a dead end. If you just found out that PINNs don’t perform better than traditional numeric methods to solve PDEs, you should still publish your findings. So future researchers have a better idea of what to ignore and what to improve.
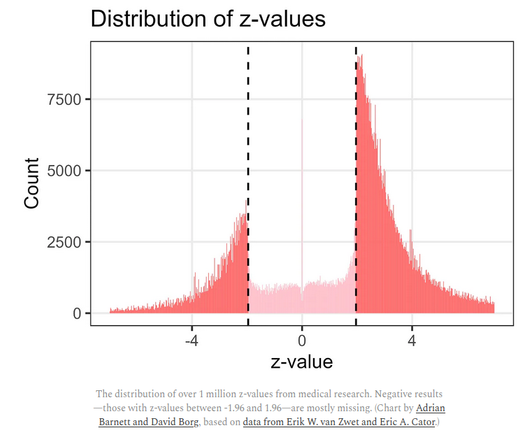
Arbitrary success thresholds: academia has set very arbitrary thresholds to measure the statistical significance of a given result. If everything below a given sigma is statistically insignificant, and everything above is statistically significant, then researchers are unlikely to publish potentially significant results that just so happened to yield a z-value slightly below the threshold (often because of insufficient or bad data), are instead incentivised to publish results that passed the threshold just by a hair, and may otherwise massage their data until it fits the threshold. This is eventually the biggest reason behind the replicability issue in modern science.
Conflict of interests: AI adoption is exploding among scientists less because it benefits science and more because it benefits scientists themselves. Studies that involve AI get big funding by names such as Google, Microsoft and Nvidia, while almost everybody else struggles for the breadcrumbs. And big companies who have invested big money in AI benefit from the narrative that AI is the tool that can solve a lot of problems in science - and this conflict of interests should be called out more often. Because of so much attention in the field, writing a paper that involves AI in some form means that your publication will receive on average 3x the numer of citations. So researchers who work on AI often end up working backwards. Instead of identifying a problem and then trying to find a solution, they start by assuming that AI will be the solution and then looking for problems to solve. Science shouldn’t be a game of hammers looking for nails.
To be clear, I believe that AI can be a very helpful tool in science.
There are fields where AI is already proving to push progress, such as protein folding and climate models.
But this doesn’t seem to be the case for many problems where an analytical solution is required. Maybe that will change in the near future, as models become better at reasoning. But that’s not the current state. And there’s nothing wrong with admitting it. It can’t be that the original paper on PINNs ended up with 14,000 citations, in spite of its obvious cherrypicking and weak baseline, and, since no incentives were present to prove its statistical irrelevance, for years hundreds if not thousands of scientists tried to make science pretending that PINNs worked - just because we’ve created a system of incentives that rewards those who believe that everything is a nail, and AI is the hammer for everything.
@ai @science
https://www.understandingai.org/p/i-got-fooled-by-ai-for-science-hypeheres