
RT @DaniloJRezende
Tired of reading about AI doom?
Read about ML for quantum field theory in arbitrary space-time dimensions :)
https://arxiv.org/abs/2305.02402
Tired of reading about AI doom?
Read about ML for quantum field theory in arbitrary space-time dimensions :)
https://arxiv.org/abs/2305.02402
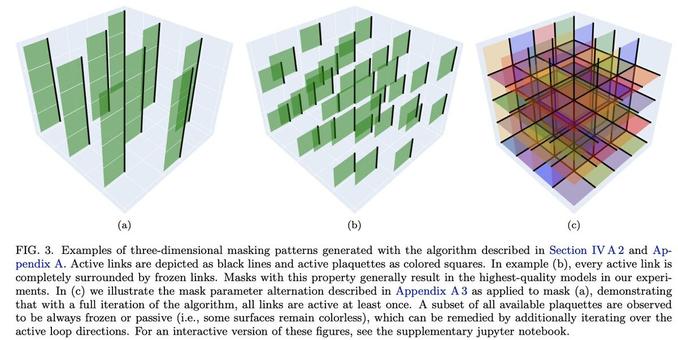
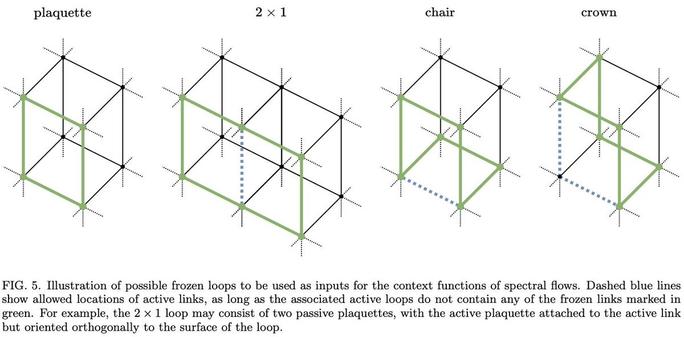

Normalizing flows for lattice gauge theory in arbitrary space-time dimension
Applications of normalizing flows to the sampling of field configurations in lattice gauge theory have so far been explored almost exclusively in two space-time dimensions. We report new algorithmic developments of gauge-equivariant flow architectures facilitating the generalization to higher-dimensional lattice geometries. Specifically, we discuss masked autoregressive transformations with tractable and unbiased Jacobian determinants, a key ingredient for scalable and asymptotically exact flow-based sampling algorithms. For concreteness, results from a proof-of-principle application to SU(3) lattice gauge theory in four space-time dimensions are reported.


