Working with autoregressive generation loops? "When Autoregressive Loops Stay Friendly" explores keeping them fast without making them painful to work on.
👉 https://zalt.me/blog/2026/06/autoregressive-loops-friendly

Working with autoregressive generation loops? "When Autoregressive Loops Stay Friendly" explores keeping them fast without making them painful to work on.
👉 https://zalt.me/blog/2026/06/autoregressive-loops-friendly
Threat Actors Leverage AI for Vulnerability Exploitation and Cyber Operations
Google Threat Intelligence Group has spotted a threat actor using a zero-day exploit likely developed with AI, marking a chilling new trend in cybercrime. This game-changing tactic turbocharges exploit development, malware autonomy, and access to premium AI services.
#AiVulnerabilityExploitation #ZeroDay #GenerativeModels #ThreatIntelligence #GoogleThreatIntelligenceGroup
Die kommende EU Regulierung, Alltag und Urheberrecht.
Heute zum Feiertag ein kleiner Einschub - das größere Thema folgt bereits Sonntag den 03.05 mit einer Betrachtung, wie wir Cloud-KI's entfliehen könnten - wenn wir wollten.
#autonomeAgenten #EUAIAct #GenerativeModels #Datensicherheit
"In this exploration, I have come to understand why one would use #generativemodels to accomplish a specific goal, and how they can be successful in doing so. I don't think condemning people for using them is that helpful to anyone, or to whatever cause you're fighting for so fervently that condemning someone seems worthwhile.
These models, like the people who use them, are not one thing. They look different in different lights, held at different angles. Dangerous, awesome, seductive, effective, beneficial, corrupted—all this and more. And we of course are all sinners. The only way I have found to survive this world is together, reaching out with grace and understanding to those who do not see the world as we do, who do not act as we do. It is much harder than anger and #condemnation. That's part of why I'm sure it's the right thing to do. It also feels a lot better to reach out a hand than strike with closed fist."
Hands on with AI audio generation: GAI voice, music, and sound effects
This is the second post in a series exploring the multimodal possibilities of generative AI. This series will take a detailed, hype-free look at text, image, audio, video, and code generation and explore the creative potential as well as the ethical concerns of GAI. Although Generative AI isn't a new technology, it's definitely been having a hype moment since the release of ChatGPT in November 2022. Unfortunately, the focus has been squarely on the text-based chatbot at the exclusion of […]



New research shows AI‑enabled disinformation swarms can flood social platforms, weaponising generative models and AI agents to sway public opinion and undermine democratic governance. Learn how these influence campaigns operate and what can be done. #AISwarms #Disinformation #DemocraticGovernance #GenerativeModels
🔗 https://aidailypost.com/news/ai-enabled-disinformation-swarms-threaten-democratic-governance

AI labs are racing on multiple timelines, but without breakthroughs in memory and caching, generative models will hit a wall. Nvidia and OpenAI are pushing hardware limits, yet data‑center consolidation may be the real bottleneck. Find out why memory management is the next frontier for scaling AI. #AI #GenerativeModels #MemoryManagement #DataCenter
🔗 https://aidailypost.com/news/multiple-ai-bubbles-have-different-timelines-labs-need-memory-caching

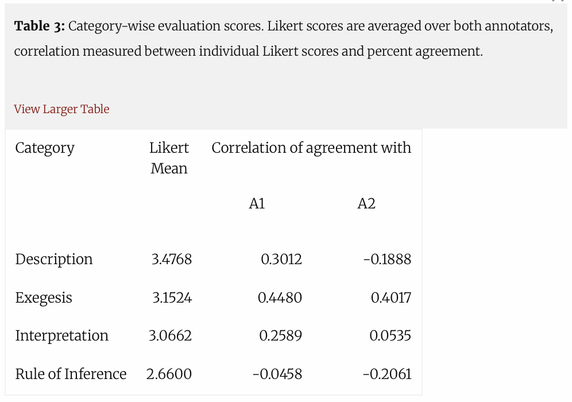
🔍🧠 Their experiments show that #LLMs can produce reasonable poem descriptions, but struggle with more abstract interpretion, highlighting where #NLG currently meets its #limits in #LiteraryInterpretation.
Flavio Adamo (@flavioAd)
작년에는 존재하지 않았던 최신 LLM 및 모델들이 빠르게 등장했다고 알리는 목록 트윗입니다. 예로 DeepSeek: R1, Qwen2.5-Max, Sonar Reasoning, Mistral Small 3, o3 Mini, Gemini 2.0(Flash-Lite/Pro/Flash), Llama-3.1-70B-Instruct, o3 Mini High, Grok-3, Saba, Claude 3.7 Sonnet 등을 열거하며 작년 대비 급격한 생태계 변화를 강조합니다.

Just a reminder that none of this existed last year: DeepSeek: R1 Qwen2.5-Max Sonar Reasoning Mistral: Mistral Small 3 o3 Mini Mistral Small 3 Gemini 2.0 Flash-Lite Gemini 2.0 Pro Google: Gemini 2.0 Flash Llama-3.1-70B-Instruct OpenAI: o3 Mini High Grok-3 Saba Claude 3.7 Sonnet


