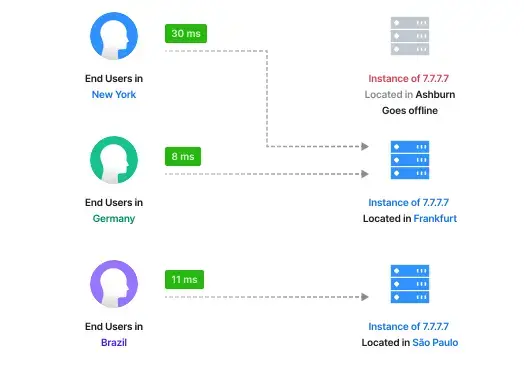
woo! connected to a test instance of prosody xmpp on port 443 (https) using xmpp's direct-tls protocol
which means
- hopefully, certain employers won't block the traffic anymore
- hopefully, it can pass through sniproxy the same way https traffic does, which will enable ipv4 users to talk to my ipv6 xmpp server
there's still different ways i can think of to wire all this together, wondering if any would be better