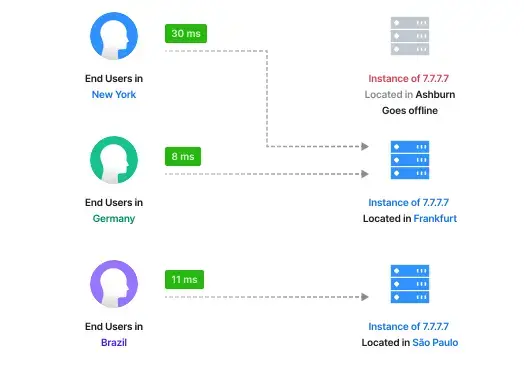
my prosody xmpp setup in its new server mostly works great (assuming ipv6 capable network) but somewhere i've introduced a timeout that closes the connection after a uniform number of seconds
pretty sure it has something to do with haproxy, though from a skim of the docs these timeouts are supposed to apply to the initial connection setup, not inactivity
also after a chat with someone more knowledgeable i think i'm resigned to eventually acquire that ipv4 address