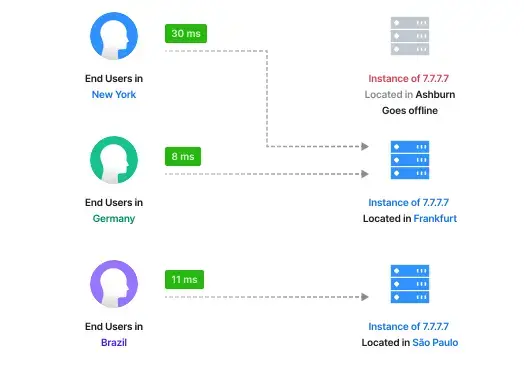
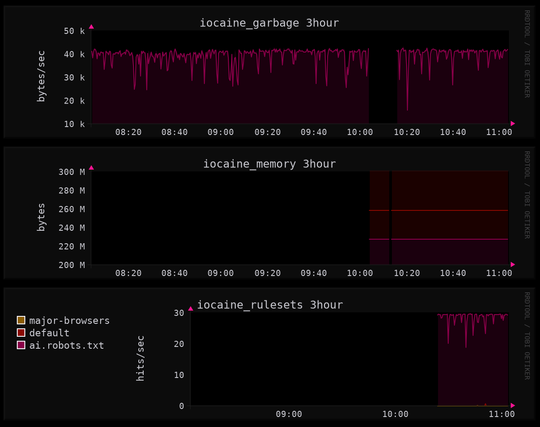
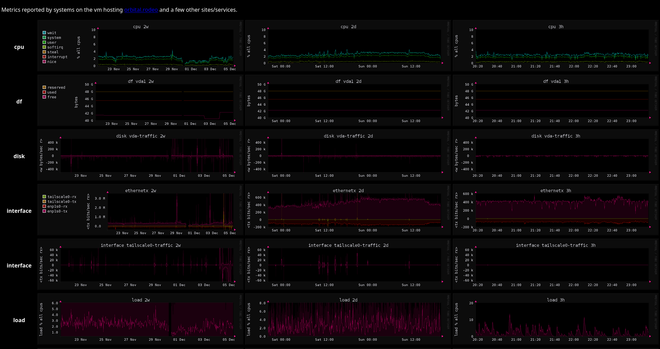
wait, how often does the whole region disappear anyway?
that was never a concern multiple employers ago when i got to help out at the datacenter
they did redundant everything inside the rack, regular cable-yank failover tests and everything, but no geographical redundancy iirc
maybe i'll inquire about a vm on another host within the same rack when i get closer to dragging clients on board and just forget about higher availability than that for now