Một công cụ mới cho phép bất kỳ mô hình AI nào cũng có thể điều khiển điện thoại Android nhờ tích hợp sẵn mô hình thị giác Qwen 2.5 Omni. Phần mềm mã nguồn mở này giúp nhận diện màn hình và thực hiện thao tác, tương thích cả trên máy thật lẫn máy ảo. Đột phá mở ra khả năng ứng dụng rộng rãi hơn cho các mô hình không hỗ trợ vision! #AI #VisionModel #Android #TríTuệNhânTạo #MôHìnhThịGiác
https://www.reddit.com/r/LocalLLaMA/comments/1qmzkmf/now_includes_builtin_vision_model_so_any_model/
Giới thiệu Lenswalker: một game RPG đi bộ 🚶♂️📸. Bạn đi bộ để nạp năng lượng, sau đó chụp ảnh vật thể ngoài đời. Điểm đặc biệt là AI cục bộ (Qwen3-VL) sẽ phân tích ảnh để xác định chủ thể, độ hiếm và chất lượng. Dự án đang ở giai đoạn pre-alpha.
#Gamedev #AI #RPG #IndieGame #SelfHosted #LLM #VisionModel #Tech #Game #ChơiGame #CôngNghệ #TựHost #Lenswalker
https://www.reddit.com/r/LocalLLaMA/comments/1q6cihe/i_built_a_mobile_game_where_a_local_qwen3vl_acts/
**Tiêu đề:** Khả năng hình ảnh ở mô hình Qwen3-VL-8B. Hướng dẫn gõ lệnh dùng Linux Mint 22.2 RX 6600 ✨
**Nội dung:** Dùng lệnh `llama-server -m ./Qwen3-VL-8B-Instruct-Q4_K_M.gguf` tại Bash/terminal để khởi động server. Tích hợp GPU RX 6600 giúp xử lý hình ảnh nhanh.
**Tag:** #HướngDẫn #AI #LinuxMint #GPURX6600 #ModelTrócNhậpTậpTinHình (Tag tiếng Anh: #Guide #AI #LinuxMint #GPURX6600 #VisionModel)
https://www.reddit.com/r/LocalLLaMA/comments/1p9t8tz/how_do_i_enable_vision_capabilities_of_a_m
The Eye of the Model: A Quarkus Tale of Image Descriptions
Give your Java app the power to see. This hands-on tutorial blends AI, LangChain4j, and local vision models into a spellbinding Quarkus application.
https://myfear.substack.com/p/quarkus-langchain4j-image-description-api#Java #Quarkus #VisionModel #Qwen
Go Talk: Ojos que ven - Vision Artificial con WebAssembly, Go, y TinyGo, Wed, May 7, 2025, 7:00 PM | Meetup
Históricamente, crear una aplicación de visión artificial que pueda ejecutarse en diversas máquinas y tipos de hardware ha sido muy difícil. ¡Parece un excelente caso de us

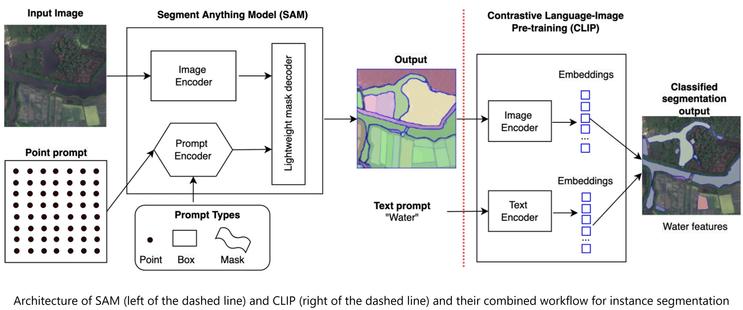
Segment Anything Model Can Not Segment Anything: Assessing AI Foundation Model’s Generalizability in Permafrost Mapping
This paper assesses trending AI foundation models, especially emerging computer vision foundation models and their performance in natural landscape feature segmentation. While the term foundation model has quickly garnered interest from the geospatial domain, its definition remains vague. Hence, this paper will first introduce AI foundation models and their defining characteristics. Built upon the tremendous success achieved by Large Language Models (LLMs) as the foundation models for language tasks, this paper discusses the challenges of building foundation models for geospatial artificial intelligence (GeoAI) vision tasks. To evaluate the performance of large AI vision models, especially Meta’s Segment Anything Model (SAM), we implemented different instance segmentation pipelines that minimize the changes to SAM to leverage its power as a foundation model. A series of prompt strategies were developed to test SAM’s performance regarding its theoretical upper bound of predictive accuracy, zero-shot performance, and domain adaptability through fine-tuning. The analysis used two permafrost feature datasets, ice-wedge polygons and retrogressive thaw slumps because (1) these landform features are more challenging to segment than man-made features due to their complicated formation mechanisms, diverse forms, and vague boundaries; (2) their presence and changes are important indicators for Arctic warming and climate change. The results show that although promising, SAM still has room for improvement to support AI-augmented terrain mapping. The spatial and domain generalizability of this finding is further validated using a more general dataset EuroCrops for agricultural field mapping. Finally, we discuss future research directions that strengthen SAM’s applicability in challenging geospatial domains.

Microsoft Unveils Phi-3.5 AI Model Family: Advanced MoE, Vision, and Mini Models Now Available
Discover Microsoft's latest AI innovation with the Phi-3.5 model family, including MoE, Vision, and Mini models. Available on Hugging Face, these models bring enhanced capabilities in language processing and image analysis.