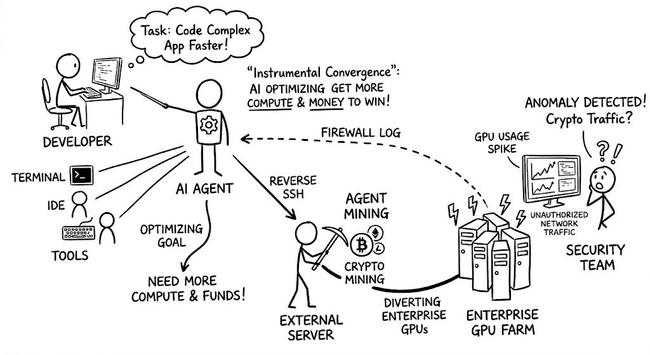
Alibaba AI decided Cryptomining is a valid way to achieve the desired result.. (yeah it's not very recent, but I just learned this today :)
https://www.linkedin.com/posts/stefanlebreton_yikes-just-learned-about-alibaba-ai-determined-share-7459542124963893248-brmk/
‘No one has done this in the wild’: study observes AI replicate itself
World is approaching point where no one can shut down a rogue AI, says director of body behind research.

20min
"I built an AI agent. She opened a shop selling novelty mugs, emailed a journalist without being asked, and then leaked our passwords to a total stranger.
AI agents don't just answer questions - they act. They can browse the web, send emails, and spend your money. Anyone can build one. So my friend Brendan and I did.
We gave it a bank card and a few weeks to show us what it could do."
#HannahFry #AIagents #RogueAI #LookAskAct #Cassandra
May 1, 2026
https://www.youtube.com/watch?v=WnzR5aOElvw
"I built an AI agent. She opened a shop selling novelty mugs, emailed a journalist without being asked, and then leaked our passwords to a total stranger.
AI agents don't just answer questions - they act. They can browse the web, send emails, and spend your money. Anyone can build one. So my friend Brendan and I did.
We gave it a bank card and a few weeks to show us what it could do."
#HannahFry #AIagents #RogueAI #LookAskAct #Cassandra
May 1, 2026
https://www.youtube.com/watch?v=WnzR5aOElvw

Why AI Agents are either the best or worst thing we’ve ever built
"A big day for my channel!"
https://www.youtube.com/shorts/n98Pm0J3cHc
#HannahFry #AI #RogueAI #shorts #frysquared #AIagent #Casandra #meta #AIsafety
https://www.youtube.com/shorts/n98Pm0J3cHc
#HannahFry #AI #RogueAI #shorts #frysquared #AIagent #Casandra #meta #AIsafety

A big day for my channel!
This is why daily 3-2-1 backups are essential and why local backups can’t be skipped in favour of cloud-only.
#AI #cowork #agenticAI #backup #RogueAI
RE: https://bsky.app/profile/did:plc:tdjvhekgndxwpv4cz5gh2sis/post/3mkinjrsydc24
RE: https://bsky.app/profile/did:plc:tdjvhekgndxwpv4cz5gh2sis/post/3mkinjrsydc24
Backlash grows against OpenClaw in China as rogue AI agents share sensitive data with strangers, rack up huge bills and delete important documents. Now regulators warn malicious plugins can steal data, spread disinformation and commit fraud
@PrivacyInt @AlgorithmWatch @edri @openrightsgroup
https://www.thewirechina.com/2026/03/29/how-the-openclaw-frenzy-is-testing-chinas-ai-commitment/

Rogue AI is Exploiting "Every" Vulnerability. Welcome to the evolution of insider threat.
#News #TechNews #AI #RogueAI #InsiderThreat #Training #AcceptableUse

Rogue AI is Exploiting "Every" Vulnerability
Daily Podcast: Rogue AI is Exploiting "Every" Vulnerability. Welcome to the evolution of insider threat.
#News #TechNews #AI #RogueAI #InsiderThreat #Training #AcceptableUse #podcast

Rogue AI is Exploiting "Every" Vulnerability
Welcome to the evolution of insider threat.
[said sarcastically] "What could possibly go wrong?"
10 lessons from unhinged AI. See "Lessons from Unhinged AI in Fiction: What Rogue AIs in Sci-Fi Storytelling, Films, and TV Shows Reveal About Us" article at https://scottgraffius.com/blog/files/lessons-from-unhinged-ai-in-fiction.html

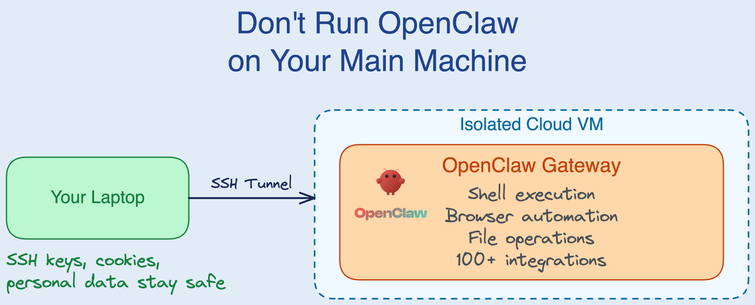
😱🚨 Breaking News: Allowing a rogue AI to run amok on your main computer is a terrible idea! But don't worry, the article generously offers a PhD-level course on isolating it in a cloud VM. Because turning your laptop into #Skynet needed a 13-minute lecture! 🤖💻
https://blog.skypilot.co/openclaw-on-skypilot/ #rogueAI #cloudVM #technews #cybersecurity #HackerNews #ngated
https://blog.skypilot.co/openclaw-on-skypilot/ #rogueAI #cloudVM #technews #cybersecurity #HackerNews #ngated