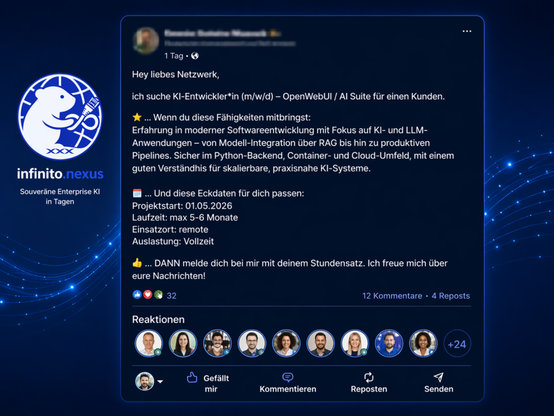
Souveräne Enterprise KI in Tagen statt Monaten mit Infinito.Nexus
Der gezeigte Post steht exemplarisch für eine Entwicklung, die aktuell in vielen Unternehmen zu beobachten ist. Es werden kurzfristig KI Entwicklerinnen und Entwickler gesucht, die ein breites Spektrum abdecken, von LLM Integration über RAG bis hin zu produktiven Pipelines und skalierbaren Cloud und Container Umgebungen. Der Bedarf ist hoch, die Anforderungen komplex und die Zeitfenster meist sehr eng.
Dabei zeigt sich immer wieder, dass die eigentliche Herausforderung nicht nur im Finden einzelner Expertinnen und Experten liegt, sondern in der fehlenden technischen Grundlage, um solche Lösungen schnell, sicher und nachhaltig umzusetzen.
[…]
https://blog.infinito.nexus/blog/2026/04/22/souverane-enterprise-ki-in-tagen-statt-monaten-mit-infinito-nexus/