Current DNA analysis methods assume our matches are only related in one way. What if that's not the case?
https://thednageek.com/jan-and-the-complex-pedigree-analysis/
#pedigreecollapse #endogamy #doublecousins #BanyanDNA #DNAanalysis

Jan and the Complex Pedigree Analysis
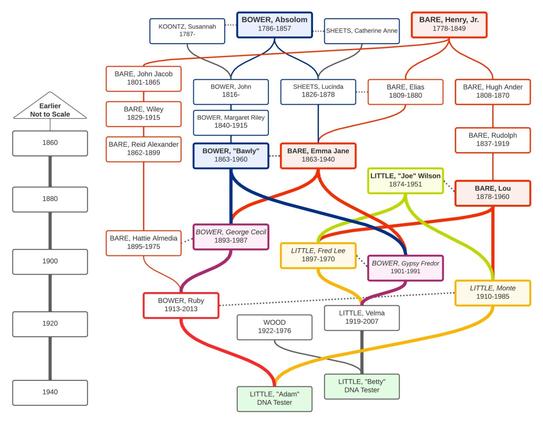
Annemarie's grandparents were Anna and Jan, Afrikaners in South Africa. They married when Anna was 18 (her first marriage) and Jan was 36 (his second). Jan was the younger brother of Anna's stepfather Andries, who married Anna's mother, Maria and fathered Anna's half sister Igna. With me so far? [caption id= align=alignleft width=347] The paper-trail for Anna and Jan[/caption] How much DNA can we expect the children of Anna and Jan to share with a grandchild of Andries and Maria? They would be half first cousins (h1C), because Igna and Anna were half sisters and also first cousins once removed (1C1R) through the brothers Jan and Andries. If so, we'd expect them to share ≈425 cM through the first relationship and another ≈425 cM through the second, totaling approximately 850 cM, the same amount as full first cousins. But they didn't. S, the granddaughter of Andries and Maria, shares only 679, 635, and 592 cM with three daughters of Anna and Jan (M, A, and A, respectively). What's more, P, a grandchild of Jan's first marriage, shares only 156 cM with S, on the low end for the expected 2C relationship. Are these observations just normal variation, or do they mean something more? Annemarie suspected that Jan might have been a half brother to Andries or might even have been adopted into the family. How can we tell? Annemarie's question, posted to The DNA Roundtable Facebook group, is a fabulous opportunity to explore complex pedigree analysis. DNA-based Relationship Tools Tools like the Shared cM Tool and What Are the Odds? can indicate which relationships are most likely for two or more people based on how much autosomal DNA they share. Basically, a computer program simulated thousands of first cousins and thousands of second cousins (and so on) to see what the typical shared DNA amounts are for each. With a little more analysis, we can then compare what's expected for a given relationship with what we actually see. However, those tools assume everyone is related only once. That's obviously not the case here. For Annemarie's question, we need data that can account for the double relationship between S and M+A+A. We need custom simulations. A couple of software tools are available that can do such simulations for genetic genealogy, but they are not for the faint of heart, and they don't do the statistical analyses we need to test genealogical hypotheses. I used one called Ped-sim to help Annemarie after making some tweaks to the workflow to align it better with the DNA tests we use for genealogy. (For the nerdy: I used sex-specific crossover rates, accounted for crossover interference, and used a genetic map of ≈3500 cM.) The Hypotheses I tested three hypotheses for Jan's place in the tree: Hypothesis 1 (H1): He was a full brother to Andries. Hypothesis 2 (H2): He was a half brother to Andries. Hypothesis 3 (H3): He was a first cousin to Andries and adopted by Andries' mother. In the diagrams below, the hypotheses are shown in black, and the DNA testers are in blue. The branch in question is red. The table below shows how each pair of DNA testers would be related to one another under each hypothesis. Because M, A, and A are full siblings to one another and have the same relationships to S and P, they were treated as one entity, MAA. Next, I simulated DNA match data between S and MAA and between S and P for each hypothesis. Note that the relationship between P and MAA is the same for all three hypotheses, so there was no need to simulate or analyze those matches. I did 10,000 simulations for each relationship pair for each hypothesis, and used the results to generate expected histograms that we can compare to the actual match data. Were Jan and Andries Brothers? Total cM This first set of histograms shows the total amounts of shared DNA between S and P (top of figure) and between S and MAA (bottom). In each figure, the histograms represent, from left to right, H3 (blue), H2 (green), and H1 (red). The black arrowheads mark the actual shared DNA amounts. The highest bar beneath each arrowhead is the most likely relationship for that match. The match between S and P is equivocal between H1 and H2 (the bars are almost the same height) but strongly disfavors H3. Eyeballing the bar heights, I estimated the probabilities at ≈51% for H1, ≈46% for H2, and ≈3% for H3. The matches between S and M, A, and A all favor H2, with rough probabilities of ≈49%, ≈54%, and ≈54%. I also calculated an odds ratio (i.e., a WATO-type score) for each hypothesis by multiplying the individual probabilities to get a compound probability, then dividing by the smallest one to convert to odds ratios. The WATO scores were 1 for H1, 60 for H2, and 1 for H3. This is considered strong support for H2. Number of segments Next, I analyzed the number of segments shared by S and P (top of figure) and by S and MAA (bottom). This time, the match between S and P strongly favored H1 (≈93%) over the other two hypotheses. The MAA siblings' matches to S individually favored three different hypotheses (bottom), although H2 was the only hypothesis that was not strongly disfavored by any of the three matches. Its individual probabilities for the three siblings were ≈38%, ≈38%, and ≈51%. Again, I calculated the odds ratios for each hypothesis, this time based solely on the number of shared segments. The scores were 12 for H1, 47 for H2, and 1 for H3. This is strong support for H2 over H3 but only moderate support for H2 over H1. Longest segment The third factor considered was the size of the longest segment. For S and P (top of figure), H1 and H2 were equally probable at ≈39%. The matches between S and the three siblings (bottom) all slightly favored H1 (≈39%, ≈48%, and ≈39%). For all four pairwise matches, the second most likely hypothesis was H2 at ≈35%, ≈30%, and ≈35%. The odds ratios for longest shared segment were 8 for H1, 4 for H2, and 1 for H3. There was no meaningful difference between H1 and H2, and both had moderate support over H3. Combined odds ratio When all three factors are considered together (total cM, # segments, and longest segment), the results are unequivocal: Hypothesis 2 is very strongly supported with an odds ratio of 11,666, compared to 112 for H2 and 1 for H3. Thus, this analysis provides robust evidence that Jan and Andries were half brothers, not full brothers or first cousins. The Next Frontier Complex statistical analyses like this one are the future of genetic genealogy. Such analyses will allow us to address genealogical puzzles that are currently out of reach of autosomal DNA due to pedigree collapse, endogamy, and even incest. They can even let us leverage the DNA results of multiple close relatives to investigate research questions further back in our trees. However, the work done for this blog post was both technical and tedious, and more sophisticated statistical analyses are available. A tool called BanyanDNA is currently in beta testing that will make complex hypothesis testing accessible to a much broader audience. If you come from an endogamous population, you can help us to tailor the tool to your needs by submitting known match data to this survey. You can also sign up for the BanyanDNA mailing list to be among the first to hear about opportunities to beta test the tool and our official product launch at RootsTech 2024.