https://rollo75.blogspot.com/2025/11/horse-3495-us-government-shutdown-is.html - blogged
The US Government Shutdown Is Just "The Matthew Effect" Being Played Out Again
https://rollo75.blogspot.com/2025/11/horse-3495-us-government-shutdown-is.html - blogged
The US Government Shutdown Is Just "The Matthew Effect" Being Played Out Again
when quality is tough to measure objectively, reputation often takes its place and the #Mattheweffect takes over. Well-known names get the recognition, even if their work isn’t actually superior. 🤷♀️📚

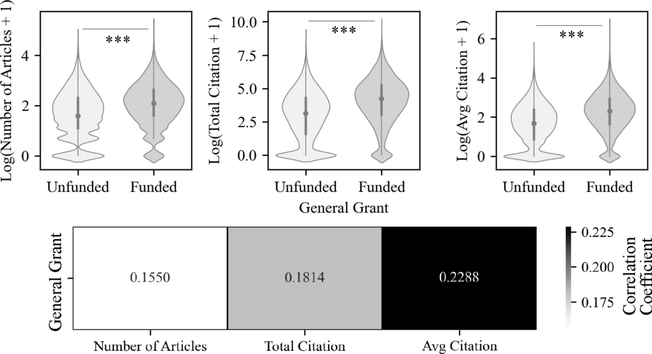
Do researchers from prestigious universities have an unfair advantage in securing research funding? 📊 A new study on China's #NSFC grants confirms the #MatthewEffect — the rich get richer in academia:
 https://doi.org/10.1007/s11192-025-05278-2
https://doi.org/10.1007/s11192-025-05278-2
Should funding be prestige-blind? 🤔 I'd advocate for anonymized applications to prevent institutional bias.
#ScienceFunding #AcademicInequality #Scientometrics #UniversityPrestige

Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
New study: "While #LLMs can aid in citation generation, they may also amplify existing biases, such as the #MatthewEffect, and introduce new ones, potentially skewing scientific knowledge dissemination."
https://arxiv.org/abs/2405.15739

Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date. In our experiment, LLMs are tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias, which persists even after controlling for publication year, title length, number of authors, and venue. The results hold for both GPT-4, and the more capable models GPT-4o and Claude 3.5 where the papers are part of the training data. Additionally, we observe a large consistency between the characteristics of LLM's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases, such as the Matthew effect, and introduce new ones, potentially skewing scientific knowledge dissemination.
Q: Is the pay-to-publish model for #OpenAccess pricing #scientists out?
A:Yes
it’s further entrenching inequality by blocking smaller and younger researchers from being able to publish in glamorous journals, reducing grant success creating a #MatthewEffect
https://www.science.org/content/article/pay-publish-model-open-access-pricing-scientists
Are grant proposal texts important for making research funding decisions? – No, they are not! 🙃
https://doi.org/10.1007/s11192-024-04968-7
In an experiment conducted by the Dutch Research Council 🇳🇱, it was found that the evaluations of grant applications did not change significantly if the experts only had access to the project summary and the applicants' CVs!
#Scientometrics #PeerReview #ResearchFunding #GrantProposal #SciencePolicy #MatthewEffect
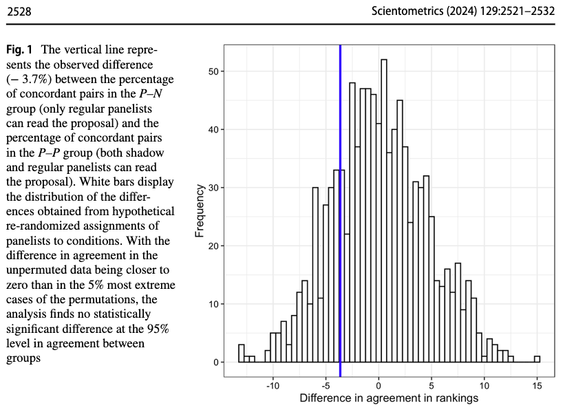

Scientists and funding agencies invest considerable resources in writing and evaluating grant proposals. But do grant proposal texts noticeably change panel decisions in single blind review? We report on a field experiment conducted by The Dutch Research Council (NWO) in collaboration with the authors in an early-career competition for awards of 800,000 euros of research funding. A random half of panelists were shown a CV and only a one-paragraph summary of the proposed research, while the other half were shown a CV and a full proposal. We find that withholding proposal texts from panelists did not detectibly impact their proposal rankings. This result suggests that the resources devoted to writing and evaluating grant proposals may not have their intended effect of facilitating the selection of the most promising science.
I have to admit that I did not read the specifics about the then announced #mastosearch. Now that the #search feature is here, I am deeply disappointed, because of the fact that it's a local search feature. In fact, I think this could be even harmful for the development of a federated social network. The big instances will have one, and this could drive users to go there. #MatthewEffect, here we come.
I want opt-in #federatedSearch, I want to be able to look beyond my bubble.
New preprint (provocation?)
📜"𝐃𝐨 '𝐛𝐚𝐝' 𝐜𝐢𝐭𝐚𝐭𝐢𝐨𝐧𝐬 𝐡𝐚𝐯𝐞 '𝐠𝐨𝐨𝐝' 𝐞𝐟𝐟𝐞𝐜𝐭𝐬?"📜
with Misha Teplitskiy
https://arxiv.org/abs/2304.06190
Quick explainer👇 https://twitter.com/HonglinB/status/1648382310155448320
When assessing the pros/cons of a policy, behavior, or norm, one compelling approach is to imagine a counterfactual world without it. This exercise reveals that even well-intentioned norms may not always result in positive outcomes #science #innovation #complexsystems #AgentBasedModels #citation #scientometrics #heuristics #mattheweffect

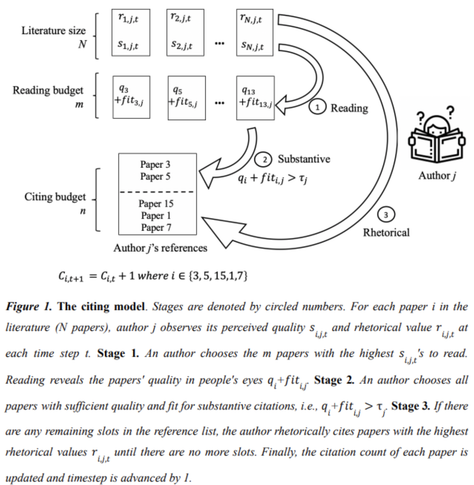
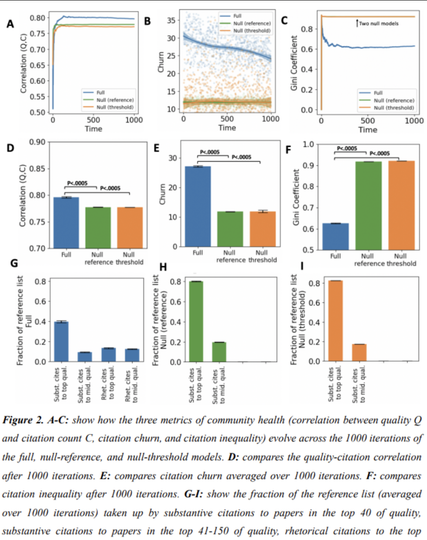
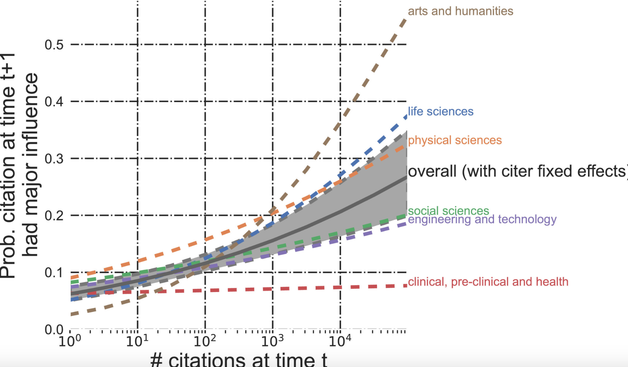

The scientific community generally discourages authors of research papers from citing papers that did not influence them because such "rhetorical" citations are assumed to degrade the literature and incentives for good work. Intuitively, a world where authors cite only substantively appears attractive. We argue that manding substantive citing may have underappreciated consequences on the allocation of attention and dynamism. We develop a novel agent-based model in which agents cite substantively and rhetorically. Agents first select papers to read based on their expected quality, read them and observe their actual quality, become influenced by those that are sufficiently good, and substantively cite them. Next, agents fill any remaining slots in the reference lists with papers that support their claims, regardless of whether they were actually influential. By turning rhetorical citing on-and-off, we find that rhetorical citing increases the correlation between quality and citations, increases citation churn, and reduces citation inequality. This occurs because rhetorical citing redistributes some citations from a stable set of elite-quality papers to a more dynamic set with high-to-moderate quality and high rhetorical value. Increasing the size of reference lists, often seen as an undesirable trend, amplifies the effects. In sum, rhetorical citing helps deconcentrate attention and makes it easier to displace incumbent ideas, so whether it is indeed undesirable depends on the metrics used to judge desirability.
