로컬 Qwen은 Claude Opus의 하위 호환이 아닌, 용도가 다른 독립적인 도구다
로컬 모델은 데이터 주권과 프라이버시가 필수적인 기업 지원 업무 및 내부 데이터 분석에서 클라우드 모델이 대체할 수 없는 실질적 가치를 제공한다.

로컬 Qwen은 Claude Opus의 하위 호환이 아닌, 용도가 다른 독립적인 도구다
로컬 모델은 데이터 주권과 프라이버시가 필수적인 기업 지원 업무 및 내부 데이터 분석에서 클라우드 모델이 대체할 수 없는 실질적 가치를 제공한다.
AI‑агент для склада в Джеймикс. Часть 2: write‑tools, безопасность, метаданные
write‑tools, безопасность, метаданные Это вторая часть статьи по Sping AI в Джеймикс. Короткая аннотация первой — на случай, если прошло время или вы её не читали: мы собрали read‑only агент внутри Джеймикс‑приложения. Пользователь задаёт вопрос на естественном языке; ChatClient из Spring AI крутит agent loop — дёргает @Tool ‑методы, пока не наберёт достаточно данных для ответа. Каждый tool данные читает через DataManager с явным fetch plan ‑ом, поэтому почти полностью остаётся внутри рамок системы безопасности Джеймикс и возвращает только нужные модели поля. UI — обычный Джеймикс‑вью, без REST ‑прослойки. Также, в первой части мы убедились, что выбор модели — не деталь: модель без надёжного native tool calling ломает всю схему. Если первую часть не читали — начните с неё, код ниже строится как продолжение. В этой части мы дадим агенту право менять данные. И вот здесь, в отличие от первой половины, начинают всплывать вопросы, которые ни Spring AI , ни большинство туториалов по агентам обычно не поднимают: под каким пользователем выполняется tool , что делать с транзакциями, как аудировать действия, инициированные моделью, и как заставить агента работать с вашей доменной моделью без ручного перечисления сущностей в промпте. Это не косметические изменения, а ровно те решения, что отделяют демо от приложения, которое можно показывать заказчику. Полный исходник всего, что мы здесь обсуждаем, лежит здесь: https://github.com/jmix‑edu/ai‑warehouse — можно клонировать и сразу запустить. Что добавляем
https://habr.com/ru/companies/haulmont/articles/1048112/
#jmix #haulmont #spring_ai #llmмодели #local_ai #java #sear #promp #demo
AI-агент для склада в Джеймикс. Часть 1
Это первая из двух статей про построение AI-агента внутри Джеймикс-приложения. Джеймикс (или Jmix , ex. CUBA ) - высокоуровневый фреймворк для разработки корпоративных приложений на Java, автор не будет слишком сильно в него погружаться, в наше время любой запрос к AI даст Вам всю нужную информацию. В этой части мы соберем минимальный, но рабочий пример: пользователь задает вопрос на естественном языке, агент решает, какие операции вызвать на бэкенде, дергает их и возвращает осмысленный ответ. В качестве предметной области возьмем склад - сценарий, узнаваемый для большинства бизнес-приложений и достаточно широкий, чтобы во второй части обсудить уже не только чтение, но и запись данных, безопасность, fetch plans и метаданные. Зачем это вообще нужно? Данные корпоративного приложения живут за списками и формами с фильтрами. Это отлично работает, когда пользователь знает, по каким полям фильтровать - и плохо для размытых, многокритериальных вопросов вроде "где у нас заканчивается кофе тёмной обжарки по северным складам?". Когда иначе пришлось бы открыть несколько экранов и руками свести результаты, AI-агент даёт возможность просто спросить - и собирает ответ из бэкенд-операций, которые у вас уже есть. Почему строить это внутри Джеймикс-приложения, а не отдельным сервисом? В случае Джеймикса агент едет на том же доступе к данным и той же безопасности, что уже есть во фреймворке, его tools идут через DataManager , поэтому он видит ровно то, что разрешено текущему пользователю - никакого параллельного пути к данным, никакого обхода прав. Именно это свойство делает агента приемлемым в enterprise-контексте, и это поведение - сквозная нить обеих частей.
https://habr.com/ru/companies/haulmont/articles/1046868/
#jmix #spring_ai #haulmont #llmмодели #local_ai #java #search #prompt #tools #demo
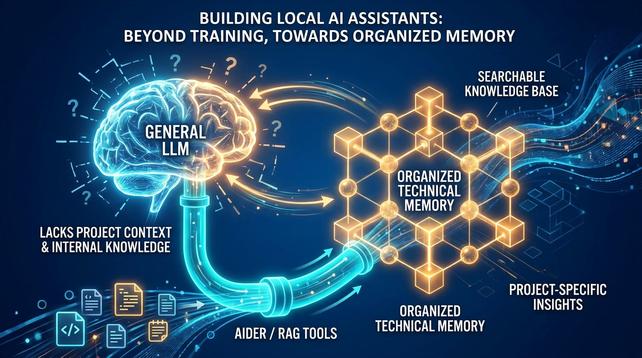
축적된 Ruby 지식을 로컬 코딩 어시스턴트로 전환하는 방법
범용 LLM은 Ruby의 일반적인 문법을 잘 알고 있지만, 특정 프로젝트의 관습이나 내부 라이브러리, 비공개 코드베이스에 대한 맥락이 부족하다는 한계가 있다.
6 моделей, 3 инфраструктурных задачи, 1 локальный AI-агент
В прошлой статье было показано, что обычный MacBook Pro M2 16GB может с оговорками решать инфраструктурные проблемы используя локальную LLM. В этой статье будут показаны результаты решения более сложных инфраструктурных задач на более тяжеловесных моделях. Мой личный выбор - Qwen3.6-35-A3B для проблем, которые сформулированы общими словами, Gemma4-26B-A4B - для чётко описанных проблем . Далее обо всём этом подробнее.
Локальный агент для диагностики инфраструктуры
В статье описаны результаты, которые получил в поисках ответа на вопрос "можно ли решать реальные задачи диагностики и исправления проблем инфраструктуры на слабом MacBook в агентском режиме (да, но)".
Чему меня научили два месяца с легковесным локальным AI-агентом
Два месяца назад openLight был маленьким pet project’ом: Raspberry Pi, Telegram-бот, SQLite и несколько команд для управления сервисами. Мне просто хотелось перестать печатать ssh [email protected] с телефона каждый раз, когда падал очередной контейнер или начинал странно вести себя Tailscale. За это время проект неожиданно превратился во что-то большее. Не в “автономного AI-агента”, а скорее в легковесный слой управления для personal infrastructure — маленьких always-on машин вроде Raspberry Pi, Mac mini, VPS или старых домашних серверов. В статье я подробно разбираю: * почему почти весь проект пришлось переписать хотя бы один раз * как deterministic-first роутинг оказался полезнее “умных” AI-агентов * зачем я отказался от идеи сложного tool calling в пользу простых и проверяемых skill’ов * почему Telegram неожиданно оказался идеальным интерфейсом для homelab-инфраструктуры; * и почему, как мне кажется, будущее локальных AI-систем будет не “магическим”, а маленьким, наблюдаемым и ремонтопригодным. Это не история про очередной AI framework. Скорее инженерная ретроспектива о том, как реальное использование быстро ломает красивые архитектурные идеи, и почему иногда один Go-бинарь, SQLite и несколько хорошо продуманных allowlist’ов оказываются полезнее огромных cloud-native систем.
Как мы запустили 35B LLM на видеокарте за $500: внутри ZINC inference engine
Год назад запуск модели на 35 миллиардов параметров подразумевал облако, очередь на GPU, и счёт от провайдера в конце месяца. Сегодня я покажу, как мы сделали это на одной потребительской видеокарте AMD за $500 — без ROCm, без CUDA, без MLX, одним бинарником на Zig. Это пост про ZINC — inference engine, который мы строим с нуля под железо, которое люди реально покупают. Не как proof of concept, а как рабочий инструмент с OpenAI-совместимым API, потоковой генерацией и встроенным чатом. Погрузиться
https://habr.com/ru/articles/1020702/
#LLM #inference #AMD #Vulkan #Zig #Metal #GPU #local_AI #Qwen #MoE
MitM-прокси для LLM
Многие разработчики в последнее время используют облачные LLM для генерации программного кода, в том числе с помощью агентов. Но это вызывает как минимум две проблемы: Утечка информации: мы не знаем, какие данные LLM передаёт в облако Бесконтрольный расход токенов, особенно в случае автоматических агентов, которые запускаются в автономную работу на длительный период Для этого есть специальные инструменты мониторинга. Например, Tokentap (бывший Sherlock) отслеживает использование токенов для LLM CLI в реальном времени на панели в консоли. Такой MitM-прокси полезен для информационной безопасности и просто для учёта расходов.
https://habr.com/ru/companies/globalsign/articles/1016612/
#MitM #Hugging_Face #llamaccp #ggml #Local_AI #Gemini_CLI #Claude_Code #OpenAI_Codex #mitmproxy #HTTPSпрокси
Почему большинство AI-агентов плохо работают на Raspberry Pi (и как я попытался это исправить)
Последнее время я экспериментировал с AI-агентами на Raspberry Pi 5 . И довольно быстро столкнулся с проблемой: большинство существующих агентных фреймворков оказываются слишком тяжёлыми для небольшого железа.
https://habr.com/ru/articles/1012258/
#LLM #AI_агент #Raspberry_Pi #golang #homelab #local_AI #open_source






