Local AI, fragmented context, and the governance problem hiding in our personal workflows
Read more 👉 https://lttr.ai/ArwJ5

Local AI, fragmented context, and the governance problem hiding in our personal workflows
Read more 👉 https://lttr.ai/ArwJ5
Local AI Gains Traction: Gemma 4 Options Expand
Learn how to install Google's Gemma 4 AI on your computer for private, offline use. Easy steps for all users.
You can now run Google's Gemma 4 AI on your own computer, offering more privacy than cloud AI. This is a big change for AI users.
#Gemma4AI, #LocalAI, #GoogleAI, #AIPrivacy, #TechNews
https://newsletter.tf/run-google-gemma-4-ai-locally-on-pc/
another #newbrew for #localAI, `exo`
> exo connects your Macs and workstations into one local inference cluster. It finds devices, reads the network, splits models across memory, and gives you normal APIs.
it's distributed. compute for inference. i'm super curious. more later but check it out yourself on their homepage; `brew install exo` hooks you up.
seems to be very oriented towards #macOS on #appleSilicon and a lot of thunderbolt.
Built for my offline AI workstation. Maybe it fits yours too.
Repo: https://github.com/llamastash/llamastash
Release blog: https://deepu.tech/introducing-llamastash
Benchmarks: https://deepu.tech/benchmarking-llamastash
⭐ welcome on the repo. Bugs welcome on the issue tracker. Feedback welcome here.
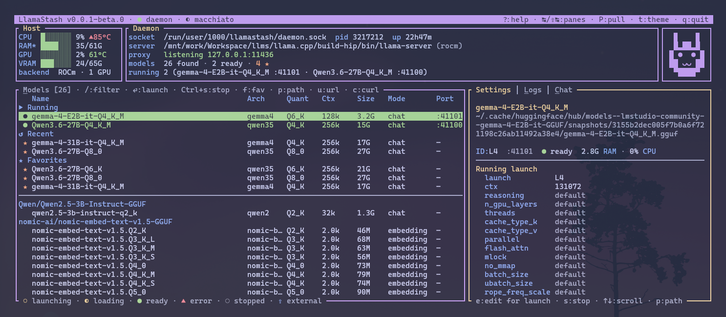
Today I'm releasing LlamaStash 0.0.2: a zero-overhead, terminal-native launcher for llama.cpp.
One Rust binary that's a TUI, a CLI, a daemon, and an OpenAI-compatible proxy.
Demo below 🧵
AI should feel like.
Close.
Private.
Available.
Useful without becoming another data pipeline.
Your first local AI host does not have to be a giant machine.
It can be your phone.
yzma 1.15 is out, needed for both breaking changes to llama.cpp & also for our new, more robust library updater.
Go get it!

Go with your own intelligence - Go applications that directly integrate llama.cpp for local inference using hardware acceleration. - hybridgroup/yzma
DuckDuckGo installs up 18% after Google I/O. Larry Ellison: "Citizens will be on their best behavior."
People are connecting the dots.
Local AI is the same instinct. Your queries, your docs, your reasoning — running on your hardware, staying in your home.
Not paranoia. Just ownership.
#LocalAI #Privacy #SelfHosted #DigitalSovereignty #OpenSource