Macrokit Studio is live on Product Hunt today 🚀
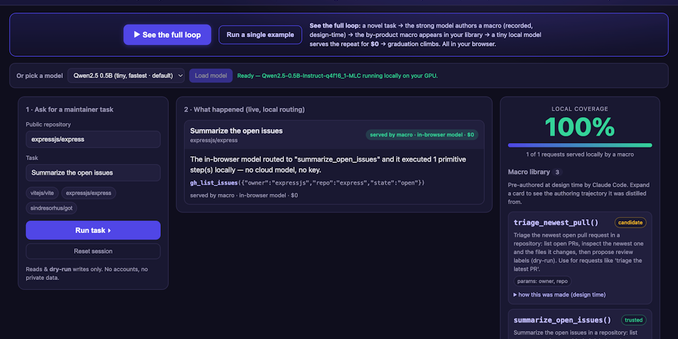
A tiny local model (WebLLM/WebGPU) does GitHub-maintainer work entirely in your browser — no signup, no API key, no server. Open the network tab and check.
Try it & tell me where it breaks:
https://www.producthunt.com/products/macrokit?launch=macrokit-studio
Open source, Apache-2.0.
Macrokit Studio: A tiny local model does frontier-grade work — free, no key | Product Hunt
Macrokit Studio is a free, open demo: a small model in your browser does GitHub-maintainer work by running macros that a strong model encoded ahead of time. No signup, no API key, no server — nothing leaves your machine (open the network tab). It's an open format for macros plus free tools to build and run them. Apache 2.0, fully open.