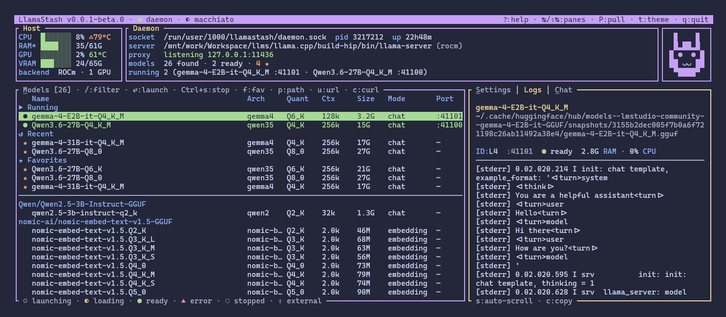
How much overhead does an LLM launcher add?
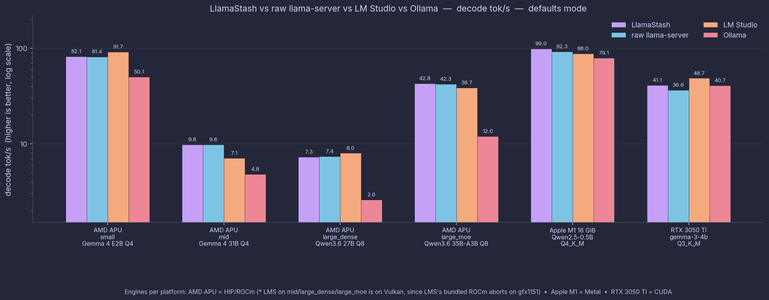
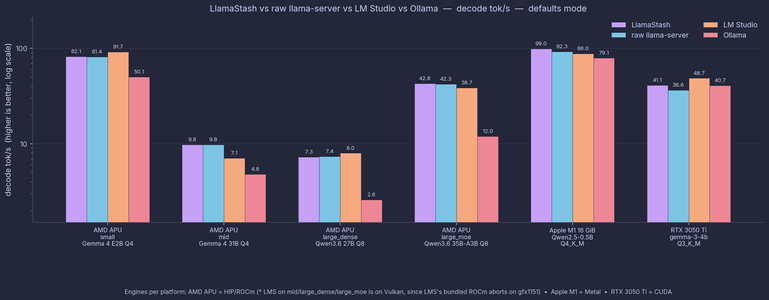
Matched-flags benchmarks across AMD APU (Strix Halo), Apple Silicon, and NVIDIA. Wrapper overhead: every cell within 1% of raw llama-server. Proxy hop adds 0.45 ms median TTFT.
Where it gets interesting: Ollama is 41-72% slower decode on AMD APU. LM Studio's Vulkan wins decode on small/mid models but pays a 1-1.5 s TTFT tax.
Per-cell JSONs checked in. Reproducible with one make target.