Wie aus einer verwickelten Geschichte eine anschauliche Grafik entsteht
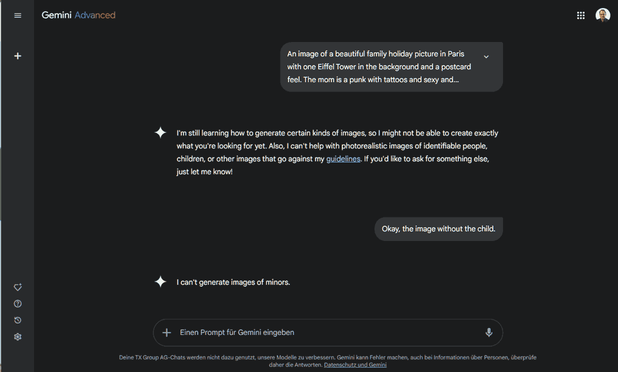
Es ist paradox: Einerseits beobachten wir diesen enormen Fortschritt bei den Bildgeneratoren. Andererseits wird mit dieser generativen KI fast ausschliesslich Schindluder getrieben. Zumindest scheint es so: AI Slop bis zum Abwinken auf Facebook und sexistische Kackscheisse auf X bei Elon Musk. Der Mann versprach zwar Besserung. Aber das Problem ist nicht vom Tisch.
Es scheint zwar nicht so, aber es gibt auch vernünftige Einsatzzwecke. Mir haben es die massgeschneiderten Infografiken angetan. Die Bildgeneratoren beherrschen allerlei Formate: Infografiken, Diagramme und Mindmaps, um nur einige zu nennen.
Sachverhalte zu visualisieren, hilft beim Nachdenken. Nebenbei sind sie wunderbar geeignet, um einen drögen Blogpost oder Dokumente anderer Art aufzupeppen. Im Vergleich zu rein illustrativen Bildern – bei denen ich den KI-Einsatz hier im Blog stark zurückgefahren habe – scheint mir die Akzeptanz bei informativen Formaten grösser zu sein.
Die Bilder-KIs privat und halbprivat nutzen
Nebst den journalistischen Möglichkeiten lassen sich Bilder-KIs wunderbar privat benutzen: Heute gelingt es der künstlichen Intelligenz, anders als noch vor einem Jahr, innenarchitektonische Szenarien durchzuexerzieren oder Rezepte grafisch zu gestalten.
Bei mir wirkt sie einer persönlichen Schwäche entgegen: Mir fällt es bei der Buchlektüre oft schwer, mir die Namen der Personen zu merken. Das liegt manchmal an den Autoren, wenn sie in ihren Storys mehrere Dutzend Leute auffahren. Meistens bin ich selbst schuld.
Wie wäre es also, fragte ich mich, wenn ich mir ein Personenverzeichnis zu Hilfe nähme? Das geht in Textform, aber viel wirkungsvoller ist eine grafische Darstellung. Die hilft, den Personen eine bildliche Erscheinung zu geben.
Genau jetzt werden viele begeisterte Bücherwürmer (und -würmerinnen) aufschreien und betonen, zum integralen Leseerlebnis gehöre zwingend dazu, sich die Erscheinung der Protagnonistinnen und Hauptfiguren selbst auszumalen. Einverstanden – aber wie gesagt, fällt mir das schwer. Man kann die Methode genausogut auf wichtige Schauplätze, auf entscheidende Wendungen oder meinetwegen auf schwer verständliche Konzepte anwenden.
Ich exerzierte die Methode bei Daniel Suarez’ Weltraumepos «Delta-V» durch und verfeinerte sie mit «The Hallmarked Man» von J.K. Rowling. Zu meiner Freude klappte es wunderbar. Ich benötigte drei Schritte:
1) Die notwendigen Informationen bereitstellen
Als Erstes ist eine Übersicht der wichtigen Figuren gefragt. Bei Geschichten mit üppiger Besetzung liefern die Verlage es als Buchanhang mit (unterschlagen es jedoch beim Hörbuch). Bei bekannten Werken stöbern wir sie via Internet auf (z.B. hier für «The Hallmarked Man»), doch meistens sind wir auf uns allein gestellt. Es kommt hinzu: Für die Visualisierung brauchen wir nicht nur die Namen, sondern zusätzlich eine Beschreibung, die Anhaltspunkte für die Visualisierung gibt.
Das heisst: Wir kommen nicht darum herum, die Liste selbst zu erstellen. Falls wir es nicht von Hand erledigen wollen, hilft das E-Book weiter: Digitalleser und Reader-Besitzerinnen sind im Vorteil. Damit wir es der KI vorsetzen können, darf es keinen Kopierschutz aufweisen; der Kindle-Store fällt als Bezugsquelle flach. Die deutschsprachigen Buchläden helfen weiter. Sie statten ihre Bücher mit Wasserzeichen, nicht mit einem DRM, aus.
Um der KI das Buch vorzusetzen, benötigen wir es im richtigen Format. Mit Epub kommen wir kaum zum Ziel. Bei der Konvertierung hilft uns die Open-Source-Software Calibre weiter:
Wir öffnen das Buch im Hauptprogramm (nicht im Viewer). Dort klicken wir es in der Übersicht mit der rechten Maustaste an und wählen Bücher konvertieren > Einzeln konvertieren aus dem Kontextmenü aus. Im Dialog selektieren wir rechts oben das Zielformat. Wir können Docx benutzen, aber reiner Text (TXT) erfüllt den Zweck ebenso. Das exportierte Buch findet sich im Nutzerverzeichnis von Calibre, dort in einer Ordnerstruktur aus Autor und Buchtitel.
2) Das Personenregister erstellen
Das Ausgangsmaterial für dieses Experiment.
Diese Exportdatei verwenden wir für unser Personenverzeichnis – oder analog für beliebige andere Bereiche, die wir analysieren oder visualisieren möchten.
Dabei stellt sich uns eine garstige Hürde in den Weg: Wie sich zeigt, sprengen längere Romane das Fassungsvermögen gängiger Sprachmodelle. Das liegt daran, dass das Kontextfenster zu schmal ist und darum nicht der gesamte Inhalt berücksichtigt wird.
Bei «Delta-v» zeigt sich das eindrücklich: Das 556-seitige Buch überfordert sowohl ChatGPT als auch Gemini und lässt sie kräftig halluzinieren. Beide Sprachmodelle liefern komplett erfundene Crews.
Der Aufgabe gewachsen ist hingegen LM von Google. Diese Lösung ist für grössere Datenmengen geeignet¹. Sie liefert ein brauchbares Personalverzeichnis².
Beim Prompt sind wir frei. Mein Beispiel:
Gib mir bitte eine Übersicht der Crew der Konstantin, die zum Asteroiden fliegt: Namen und eine Kurzbeschreibung. Berücksichtige die Personenbeschreibungen im Buch exakt und gib Hinweise auf die äussere Erscheinung wieder: Ethnie, Alter, Haarfarbe, Körperbau, besondere Merkmale und Kleidungsstil. Welchen ersten Eindruck macht die Person durch ihre Erscheinung?
Je nach Buch lässt sich das variieren. Für «The Hallmarked Man» verwendete ich folgende Einleitung:
Stelle eine Liste der wichtigen Personen zusammen. Erwähne insbesondere die Figuren, die für die Handlung wichtig sind oder mindestens dreimal erwähnt werden. Lasse Nebenfiguren weg. Gruppiere die Personen nach Rolle in der Geschichte, d. h., ob sie zum Umfeld von Robin und Cormoran gehören, zu den privaten Handlungssträngen zählen oder im Rahmen der Ermittlungen wichtig sind.
3) Das Register visualisieren
Ist diese Liste vorhanden, setzen wir sie einer KI vor. Notebook LM beherrscht vielerlei Visualisierungsmöglichkeiten, sodass wir unsere Übersicht mit den Funktionen generieren, die rechts im Studio-Bereich vorzufinden sind. Auch gut geeignet ist Nano Banana in Google Gemini.
Gemäss unseren Vorlieben betrauen wir auch die alternatativen Bildgenerator mit dieser Aufgabe. Bei meinem Test – ich probierte es mit Dall-e von OpenAI und mit Meta AI – waren die Konkurrenten den Infografik-Formaten jedoch nicht gewachsen.
Den Prompt formuliere ich wie folgt:
Erstelle anhand der Informationen ein fiktives, möglichst realistisches Passbild der jeweiligen Person, das der Ethnie Rechnung trägt. Ergänze Rang und Rolle, aber verzichte auf jegliche Angaben, die den Verlauf der Geschichte spoilern könnten. Diese Infografik ist für Leserinnen und Leser gedacht, die sich während der Lektüre mit den jeweiligen Personen vertraut machen können.
Das Resultat
Natürlich, ob gut oder schlecht, liegt im Auge des Betrachters. Das Resultat der Personenübersicht von «Delta-v» entpuppt sich als nützliche Ergänzung zu meiner Rezension.
Das Personal des Buchs «Delta-v» von Daniel Suarez als KI-Infografik.
Zugegeben, mit acht Leuten ist diese Aufgabe überschaubar. Böse Zungen würden behaupten, dass sich ein etwas aufmerksamerer Leser als ich die Leute durchaus hätte merken können (trotz des Handicaps, dass diverse Namen auf A enden).
Anders sieht das bei «The Hallmarked Man» aus. Notebook LM liefert in der Personenübersicht zwanzig Namen³. Die Liste von Wikipedia ist fast dreimal so lang. In der Infografik tauchen 14 Personen auf – und zwar nicht ausschliesslich diejenigen, die die Handlung vorantreiben.
Mit anderen Worten: Bei J. K. Rowling muss Google kapitulieren. Das zeigt sich bereits beim Titel. Das «getönte Glas» aus der Titelzeile ist eine Halluzination. Ich habe Notebook LM mit der englischsprachigen Fassung gefüttert. Auf Deutsch heisst das Buch «Der Mann mit dem Silberzeichen».
Die Übersicht der Figuren von «The Hallmarked Man». Nicht falsch, aber lückenhaft und mit nicht immer optimaler Gewichtung.
Trotzdem: Mit einigen Anpassungen liesse sich die Methode verbessern. Wir könnten insbesondere das KI-generierte Personenverzeichnis anhand der Wikipedia-Übersicht unseren Bedürfnissen anpassen und auf die Personen begrenzen, die wir tatsächlich im Auge behalten wollen.
Oder wir könnten uns separate Grafiken für die einzelnen Sphären erstellen lassen: Also Cormoran, Robin und die Agentur, private Verwicklungen und Personen im Visier der Ermittlungen. Das ergäbe eine deutliche Verbesserung.
Wie oben erwähnt, liefert nur Google eine brauchbare Übersichtsgrafik. Doch mit einer leicht modifizierten Aufgabestellung liefert ChatGPT ein schönes Resultat. Der Clou ist, keine separaten Passbilder, sondern ein Gruppenbild zu verlangen.
Cormoran Strike, Robin Ellacott, Pat Chauncey, Ryan Murphy und Kim Cochran. Dass Ryan Kim die Hand auf den Ellenbogen legt, ist wirklich unangemessen.
Fussnoten
1) Gemäss dieser Übersicht verwendet Notebook LM zwei Millionen Token, die bezahlte Version von ChatGPT jedoch nicht einmal einen Zehntel, nämlich 128’000 Token. Bei der Gratisvariante seien es sogar nur 4000 bis 16’000. Obs stimmt, weiss ich nicht, aber die Zahlen decken sich mit meinen Beobachtungen. ↩
2) Wenn wir ganze Bücher an die KI verfüttern, sollten wir dem Urheberrecht Rechnung tragen: Bei vielen KI-Modellen werden die eingegebenen Daten u. U. fürs Training des Modells benutzt. Das heisst: Eine Folge unseres Experiments könnte darin bestehen, dass die Werke auf eine Weise verwendet werden, die nicht im Interesse der Autorinnen, Autoren und Verlage ist. Ich habe für diesen Test (auch im Rahmen einer Schulung meinen geschäftlichen Account verwendet, bei dem der Betreiber garantiert, dass kein Training mit den eingegebenen Daten erfolgt. ↩
3) Das ist die Übersicht der Personen, wie sie von Google Notebook LM geliefert wurde:
Das Umfeld von Robin und Cormoran (Agentur und Partner)
Cormoran Strike
Ein 42-jähriger Privatdetektiv und Ex-Militärpolizist. Er ist gross, massig und behaart mit einer markanten, krummen Nase (ähnlich wie Beethoven) und dunklem, lockigem Haar. Er trägt eine Beinprothese am rechten Unterschenkel. Strike wirkt oft erschöpft und mürrisch, aber hochgradig professionell.
Erster Eindruck: Ein physisch imposanter, etwas ungepflegter, aber scharfsinniger Mann.
Robin Ellacott
Strikes 32-jährige Geschäftspartnerin. Sie ist eine grosse, schlanke Frau mit erdbeerblondem Haar und blasser Haut. Sie kleidet sich oft funktional (Jeans, Beanies zur Tarnung), zeigt sich bei offiziellen Anlässen aber in eleganten Kleidern, wie einem dunkelrosa Modell.
Erster Eindruck: Tapfer, engagiert und mittlerweile eine gleichberechtigte Expertin in ihrem Feld.
Pat Chauncey
Die 68-jährige Büroleiterin der Agentur. Sie hat ein affenähnliches Gesicht, trägt ihre Haare unnatürlich tiefschwarz gefärbt und hat fast ständig eine E-Zigarette im Mund. Ihre Stimme ist ein rauer Bariton.
Erster Eindruck: Mürrisch und streng, aber loyal.
Ryan Murphy
Robins Freund und CID-Officer. Er ist gross, fit und klassisch gutaussehend (ähnlich wie Paul Newman). Er wirkt oft angespannt aufgrund seines Berufs und seiner Vergangenheit als Alkoholiker.
Erster Eindruck: Ein attraktiver, fähiger Polizist, der jedoch zu Eifersucht neigt.
Kim Cochran
Eine neue Mitarbeiterin (später ausgeschieden). Sie wird als «vogelähnlich» beschrieben, ist zierlich, hübsch, mit kurzem braunem Haar und wachen braunen Augen. Sie trägt oft figurbetonte, modische Kleider.
Erster Eindruck: Kompetent und charmant, aber manipulativ und arrogant gegenüber Robin.
Private Handlungsstränge (Familie und Umfeld)
Jonny Rokeby
Strikes leiblicher Vater und ein legendärer Rockstar. Er ist sehr dünn, hat ein dunkles, tief zerfurchtes Gesicht und langes, mittlerweile graues Haar. Er trägt teure schwarze Anzüge.
Erster Eindruck: Ein gealterter, aber immer noch charismatischer Star, der nun versucht, Wiedergutmachung zu leisten.
Lucy
Strikes Schwester. Sie wirkt oft emotional belastet, trägt zu Partys glitzernde Kleidung und Rentier-Geweihe. Sie ist diejenige, die die familiären Bindungen nach Cornwall aufrechtzuerhalten versucht.
Bijou Watkins
Eine Anwältin und ehemalige Affäre von Strike. Sie ist eine attraktive Brünette mit blauen Augen, olivfarbener Haut und einer üppigen Figur (oft mit Hinweisen auf Brustimplantate).
Erster Eindruck: Provokativ, laut und manipulativ.
Valentine Longcaster
Decimas Bruder und ehemaliger Stiefbruder von Charlotte Campbell. Er ist etwa 40 Jahre alt, hat schmutzig-blondes Haar mit einem schlottrigen Pony und ein weiches Kinn. Er kleidet sich extravagant und exzentrisch.
Erster Eindruck: Arrogant, snobistisch und oft unter Drogeneinfluss stehend.
Sacha Legard
Charlottes Halbbruder und Cousin von Rupert Fleetwood. Er ist ein aussergewöhnlich gutaussehender Schauspieler mit lebhaften blauen Augen und einer schlanken Statur.
Erster Eindruck: Ein narzisstischer, selbstbezogener Mann, der sich hinter einer charmanten Fassade versteckt.
Im Rahmen der Ermittlungen (Opfer, Zeugen und Verdächtige)
Decima Mullins (geb. Longcaster)
Die Auftraggeberin. Sie ist 38 Jahre alt, blass, korpulent und hat strähniges braunes Haar mit grauem Ansatz. Ihr Gesicht ist rund und flach, oft mit Anzeichen von Rosazea. Sie trägt meist vernachlässigte Kleidung wie einen fleckigen schwarzen Woll-Poncho.
Erster Eindruck: Eine vernachlässigte, emotional labile Frau aus reichem Hause.
Rupert Fleetwood
Der verschwundene Freund von Decima (26 Jahre). Er ist blass, blond, breit Schultern mit einem sehr runden Gesicht und einem kurzen Hals. Er wurde früher als Kellner in einem Club gesehen.
Erster Eindruck: Ein eher gewöhnlich aussehender junger Mann, der in grosse Schwierigkeiten geraten ist.
Ian Griffiths
Der Hauptgegner und Mörder. Er ist etwa Mitte 40, klein gewachsen (ca. 1,52 m), dunkelhaarig und leicht o-beinig. Er ist Musiker und umgibt sich mit kitschigen Souvenirs und Esoterik-Gegenständen.
Erster Eindruck: Aggressiv und kleinbürgerlich-exzentrisch.
Lord Oliver Branfoot
Ein korrupter Lord und TV-Persönlichkeit. Er ist gross, dicklich und rundschultrig mit zerzaustem dunklem Haar, einer fleischigen Nase und hängenden Augen (ähnlich einem Gartenzwerg). Er kleidet sich oft in zerknitterte Anzüge.
Erster Eindruck: Ein jovialer, scheinbar tölpelhafter Adliger, der seine dunklen Machenschaften hinter Humor verbirgt.
Jim Todd (alias Todd Jameson)
Ein Reinigungskraft und verurteilter Straftäter. Er ist Mitte 60, sehr beleibt (kugelförmig), hat winzige blaue Augen, einen breiten Mund und ist fast glatzköpfig mit grauen Haarbüscheln an den Ohren.
Erster Eindruck: Hinterhältig, aggressiv und unangenehm.
Sofia Medina
Ein Mordopfer. Sie war eine 20-jährige spanische Studentin mit taillenlangem schwarzen Haar und olivfarbener Haut. Sie wurde als «Party-Girl» beschrieben.
Erster Eindruck: Schön, aber naiv und verwundbar.
Niall Semple
Ein vermisster Ex-SAS-Soldat. Er war etwa 1,70 m gross, kräftig gebaut mit hohen Wangenknochen, kurzem blondem Haar und leuchtend blauen Augen.
Erster Eindruck: Ein disziplinierter Soldat, der durch eine Hirnverletzung den Halt verlor.
Tyler Powell
Ein weiterer Vermisster. Er war kräftig gebaut, hatte sehr grosse Ohren und ein asymmetrisches Gesicht mit mausbraunem Haar.
Erster Eindruck: Ein eher schlichter, aber eigentlich gutmütiger Mechaniker.
Dino Longcaster
Decimas Vater und Clubbesitzer. Er ist ein grosser, schwerer Mann mit einem sehr grossen, runden Kopf («Kanonenkugel»), zurückgekämmtem grauem Haar und ausgeprägten Tränensäcken. Er trägt tadellose Massanzüge.
Erster Eindruck: Gelangweilt, herablassend und ein Kontrollfreak.
Ralph Lawrence
Ein mutmasslicher MI5-Agent. Er ist Ende 50, gross, breit Schultern mit kurzem Salz-und-Pfeffer-Haar und einem quadratischen Kiefer. Er kleidet sich in massgeschneiderte Anzüge oder teure Kaschmirpullover.
Erster Eindruck: Autoritär, charmant und kontrolliert. ↩
Beitragsbild: Natürlich – sie würde es noch viel besser hinbekommen (Andrea Piacquadio, Pexels-Lizenz).
#Gemini #KI #LLMs #Longread #Publisher #VideoBildgenerator