Can you guess what time I enabled Anubis in front of Forgejo?
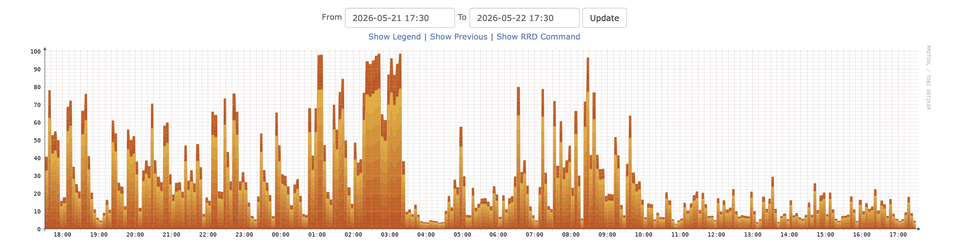
Can you guess what time I enabled Anubis in front of Forgejo?
After 615 requests over pretty much exactly 24 hours, the #aiscraper abusing #residentialproxies to try and repeatedly request one particular page on #GameSieve - 18 times successfully, before I noticed it being stuck in a loop and added another block rule - finally disappeared. However, its final request was successful and is worrying, as it came through fetch.tunnel.googlezip.net - which apparently is #Google 's Chrome Prefetch Proxy.
I've noticed requests from that range before, but always assumed that was legitimate. Do I now have to think about blocking that bit of infrastructure as well, as #scrapers have found a way to piggyback on it? Urgh!
I guess I'll start by blocking prefetching via .well-known/traffic-advice and see what that does...
Iocaine and my custom solution aren't good enough.  I'm considering to add to login to my website rewrite as protection against bots.
I'm considering to add to login to my website rewrite as protection against bots.
I would always offer an anonymous session after completing a proof of work (which is also available without JS).
Do you think this is okay? Please don't hesitate to reply!
#website #personalBlog #PersonalSites #indieweb #spam #spamprotection #scrapers #selfhosting #iocaine
| Yes, I'd would even login using Fedi or IndieAuth. | |
| Yes, I'd use the anonymous session. | |
| No, I'd avoid your website if you do that. | |
| Something else |
A couple new #scrapers to block that I haven't seen on robotstxt.com:
* Amzn-SearchBot is the search engine for Alexa and Rufus. Amazon claims on https://developer.amazon.com/amazonbot that it doesn't do AI training, but it still hammered our sites the past two days.
* SleepBot I haven't found much on, but it was requesting URLs for files that were submitted in a document upload spam attack we had a few months ago. Very sus.
Miasma: A tool to trap AI web scrapers in an endless poison pit
https://github.com/austin-weeks/miasma
#HackerNews #Miasma #AI #web #scrapers #Endless #pit #Tech #innovation #Open #source
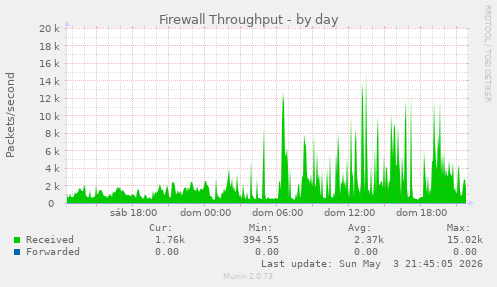
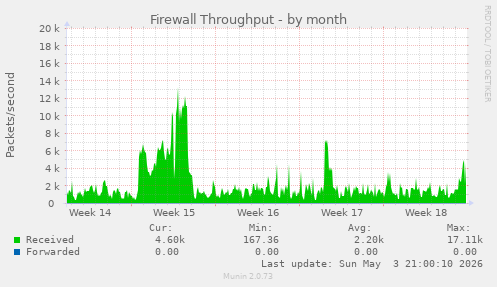
No outages in the latest Apache logs. However, there is plenty of suspicious activity.
The log has 16,033 lines.
Of these, 1,559 lines feature the "RecentChanges" function for my wikis. Which is something regular users _might_ call up from time to time, but I suspect that #scrapers are the more likely culprits.
The vast majority of these requests come from a random assortment of IP addresses, and they usually end with something on the lines of:
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
So yeah, "anonymous bot nets scraping the Interwebs for nefarious purposes" would be by first guess.


