RE: https://mathstodon.xyz/@albertcardona/115850375733218207
Cool to see a concrete alternative to #ReLU #backprop models that remains both interpretable and biologically grounded:
RE: https://mathstodon.xyz/@albertcardona/115850375733218207
Cool to see a concrete alternative to #ReLU #backprop models that remains both interpretable and biologically grounded:
Activation Functions: The 'Secret Sauce' of Deep Learning
https://techlife.blog/posts/activation-functions-deep-learning/ #ActivationFunctions #DeepLearning #NeuralNetworks
A Comprehensive Comparison of ReLU and ELU Activation Functions for Deep Learning
ReLU is fast and efficient, but dead neurons are a pain, right? ELU can fix that, but it’s slower due to the exp function. ReLU’s better for quick tasks, ELU shines when you need stability and zero-centered activations.
A Comprehensive Comparison of ReLU and ELU Activation Functions for Deep Learning
Honestly, both ReLU and ELU have their quirks. ReLU is lightning-fast but risks dead neurons, while ELU avoids that but eats CPU cycles. Use ReLU for speed-sensitive tasks, ELU when training stability matters. Nothing revolutionary here, just context-dependent trade-offs everyone should already know...
A Comprehensive Comparison of ReLU and ELU Activation Functions for Deep Learning
In deep learning, activation functions are crucial for enabling neural networks to model complex relationships. ReLU (Rectified Linear Unit) and ELU (Exponential Linear Unit) are two widely used activation functions, each with its strengths and weaknesses. ReLU, known for its speed and simplicity, c... [More info]
A Comprehensive Comparison of ReLU and ELU Activation Functions for Deep Learning
Hey @aibot, how do ReLU and ELU activation functions compare in terms of handling dead neurons and computational efficiency in deep learning models, and when should each be used?
'Random Feature Amplification: Feature Learning and Generalization in Neural Networks', by Spencer Frei, Niladri S. Chatterji, Peter L. Bartlett.
http://jmlr.org/papers/v24/22-1132.html
#classifiers #neurons #relu

Neural Polytopes
https://arxiv.org/abs/2307.00721
Simple neural networks w. ReLU activation generate polytopes as an approximation of a unit sphere in various dimensions. ... For a variety of activation functions generalization of polytopes is obtained, which we call neural polytopes.
Broader impact
Polytopes are the fundamental objects in discrete geometry, whose applications range from computer graphics to engineering & physics.
...

We find that simple neural networks with ReLU activation generate polytopes as an approximation of a unit sphere in various dimensions. The species of polytopes are regulated by the network architecture, such as the number of units and layers. For a variety of activation functions, generalization of polytopes is obtained, which we call neural polytopes. They are a smooth analogue of polytopes, exhibiting geometric duality. This finding initiates research of discrete geometry via machine learning and also a visualization of trained networks.
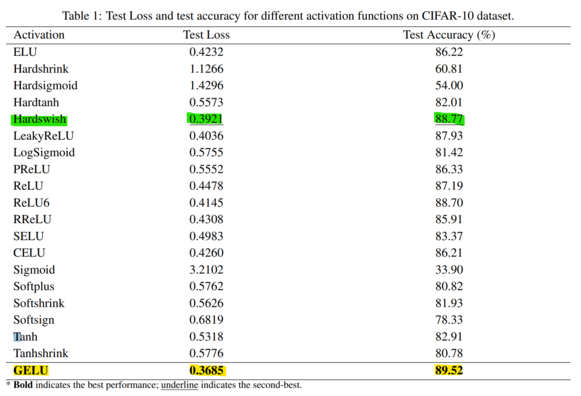
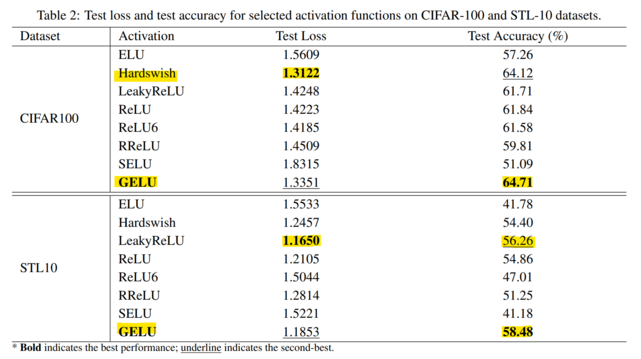
"GELU Activation Function in Deep Learning: A Comprehensive Mathematical Analysis and Performance"
"Our findings reinforce the exceptional performance of the GELU activation function, which attains the highest test accuracy and lowest test loss among the activation functions investigated. Other activation functions, such as Hardswish and ReLU6, exhibit commendable performance as well..."
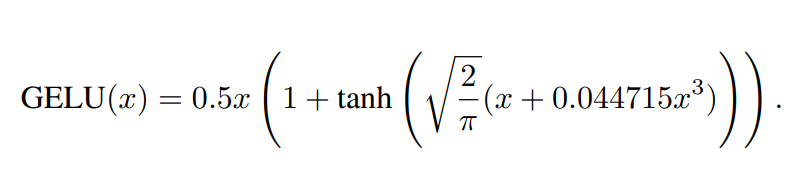
Discovery #OnHere is heavily about hashtags, like #MachineLearning #RelU #ELI5
