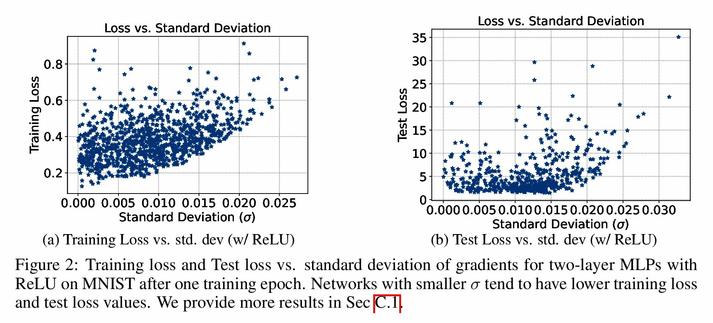
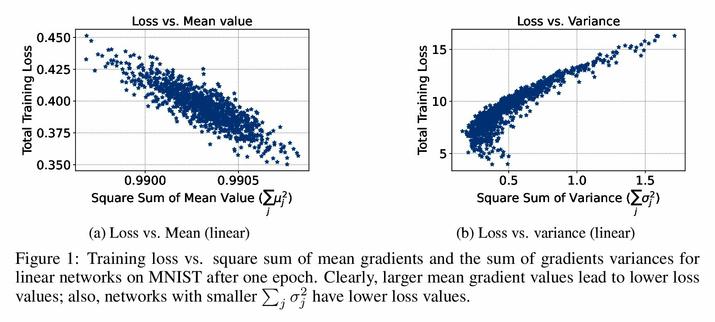
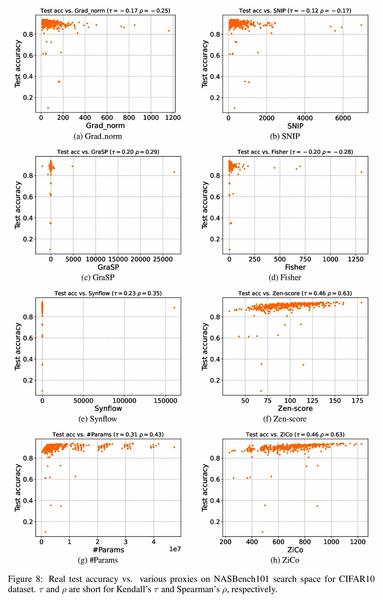
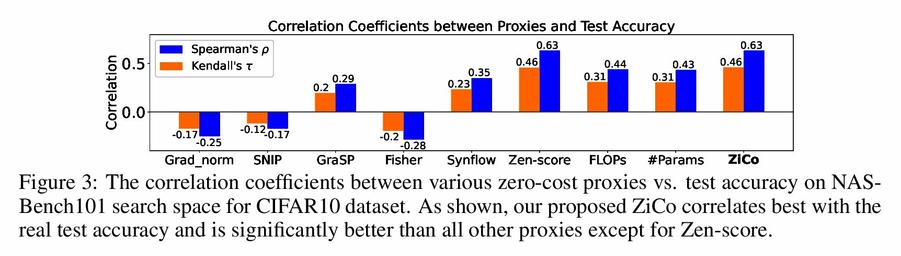
MK-UNet: Multi-kernel Lightweight CNN for Medical Image Segmentation
Md Mostafijur Rahman, Radu Marculescu
https://arxiv.org/abs/2509.18493 https://arxiv.org/pdf/2509.18493 https://arxiv.org/html/2509.18493
arXiv:2509.18493v1 Announce Type: new
Abstract: In this paper, we introduce MK-UNet, a paradigm shift towards ultra-lightweight, multi-kernel U-shaped CNNs tailored for medical image segmentation. Central to MK-UNet is the multi-kernel depth-wise convolution block (MKDC) we design to adeptly process images through multiple kernels, while capturing complex multi-resolution spatial relationships. MK-UNet also emphasizes the images salient features through sophisticated attention mechanisms, including channel, spatial, and grouped gated attention. Our MK-UNet network, with a modest computational footprint of only 0.316M parameters and 0.314G FLOPs, represents not only a remarkably lightweight, but also significantly improved segmentation solution that provides higher accuracy over state-of-the-art (SOTA) methods across six binary medical imaging benchmarks. Specifically, MK-UNet outperforms TransUNet in DICE score with nearly 333$\times$ and 123$\times$ fewer parameters and FLOPs, respectively. Similarly, when compared against UNeXt, MK-UNet exhibits superior segmentation performance, improving the DICE score up to 6.7% margins while operating with 4.7$\times$ fewer #Params. Our MK-UNet also outperforms other recent lightweight networks, such as MedT, CMUNeXt, EGE-UNet, and Rolling-UNet, with much lower computational resources. This leap in performance, coupled with drastic computational gains, positions MK-UNet as an unparalleled solution for real-time, high-fidelity medical diagnostics in resource-limited settings, such as point-of-care devices. Our implementation is available at https://github.com/SLDGroup/MK-UNet.
toXiv_bot_toot

MK-UNet: Multi-kernel Lightweight CNN for Medical Image Segmentation
In this paper, we introduce MK-UNet, a paradigm shift towards ultra-lightweight, multi-kernel U-shaped CNNs tailored for medical image segmentation. Central to MK-UNet is the multi-kernel depth-wise convolution block (MKDC) we design to adeptly process images through multiple kernels, while capturing complex multi-resolution spatial relationships. MK-UNet also emphasizes the images salient features through sophisticated attention mechanisms, including channel, spatial, and grouped gated attention. Our MK-UNet network, with a modest computational footprint of only 0.316M parameters and 0.314G FLOPs, represents not only a remarkably lightweight, but also significantly improved segmentation solution that provides higher accuracy over state-of-the-art (SOTA) methods across six binary medical imaging benchmarks. Specifically, MK-UNet outperforms TransUNet in DICE score with nearly 333$\times$ and 123$\times$ fewer parameters and FLOPs, respectively. Similarly, when compared against UNeXt, MK-UNet exhibits superior segmentation performance, improving the DICE score up to 6.7% margins while operating with 4.7$\times$ fewer #Params. Our MK-UNet also outperforms other recent lightweight networks, such as MedT, CMUNeXt, EGE-UNet, and Rolling-UNet, with much lower computational resources. This leap in performance, coupled with drastic computational gains, positions MK-UNet as an unparalleled solution for real-time, high-fidelity medical diagnostics in resource-limited settings, such as point-of-care devices. Our implementation is available at https://github.com/SLDGroup/MK-UNet.