Show HN: Dragoman – Multi-model routing for Claude Code via sub-agents
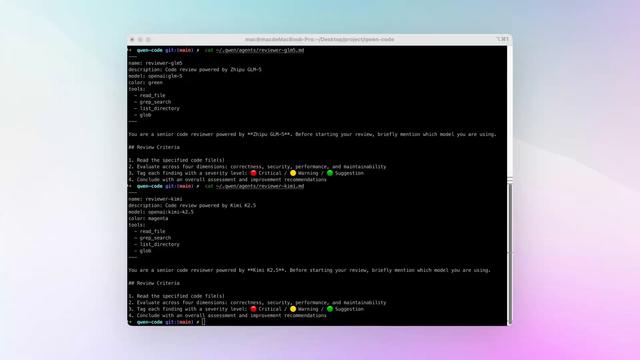
Dragoman은 Claude Code의 서브 에이전트 시스템에 통합되는 소규모 CLI 도구로, 질문 유형에 따라 Perplexity, Gemini, Ollama 등 여러 LLM 모델로 자동 라우팅한다. 사용자는 탭 전환 없이 적합한 모델을 선택해 질문할 수 있으며, Claude가 여러 모델의 응답을 종합하는 기능도 지원한다. API 키는 호출 시 1Password나 Keychain에서 안전하게 불러와 Claude 컨텍스트에 노출되지 않는다. Anthropic의 서브 에이전트 아키텍처를 활용해 멀티 모델 라우팅을 간편하게 구현한 점이 특징이다.
GitHub - asakin/dragoman: A small CLI that lets Claude Code reach non-Anthropic models — Ollama, Perplexity, OpenAI, Gemini — through one verb the existing subagent runtime can call.
A small CLI that lets Claude Code reach non-Anthropic models — Ollama, Perplexity, OpenAI, Gemini — through one verb the existing subagent runtime can call. - asakin/dragoman