Gary Marcus has a good article on METR, a think tank that evaluates AI, and how to interpret what's really going on. Some good sources for understanding here. Esp. Ramez Naam.
https://garymarcus.substack.com/p/misplaced-panic-over-ai-progress
Gary Marcus has a good article on METR, a think tank that evaluates AI, and how to interpret what's really going on. Some good sources for understanding here. Esp. Ramez Naam.
https://garymarcus.substack.com/p/misplaced-panic-over-ai-progress
AI Leaks and News (@AILeaksAndNews)
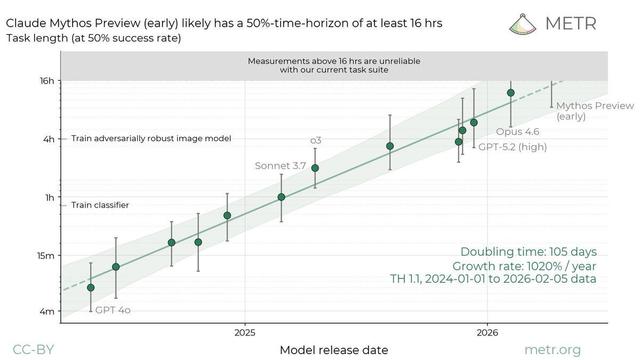
METR가 Claude Mythos Preview의 Task-Completion Time Horizon 평가를 공개했다. 50% 기준 16시간 이상, 80% 기준 3시간 수준을 기록하며 기존 평가를 넘어섰다고 설명하고, 결과를 AI 능력의 빠른 진전과 관련해 해석한다.

METR have released the Task-Completion Time Horizon for Claude Mythos Preview Scoring at least 16 hours (95% CI 8.5hrs - 55hrs) at 50% (essentially breaking METR’s eval) and 3 hours (95% Cl 1.62 hrs - 6.65 hrs) at 80% The exponential is being confirmed, welcome to fast takeoff
Jack Clark puts 60% on fully automated AI R&D by end of 2028, 30% by 2027. The case: benchmarks for every sub-skill trending up — coding (SWE-Bench ~2% → 93.9%), training-loop optimization (2.9x → 52x speedup, human 4x baseline passed three generations back), #METR time horizons (~30s in 2022 to ~12h today). The 30-vs-60 gap is a bet on how often a year-scale human insight still cracks a paradigm.
주니어 개발자 채용 14% 감소, AI가 사다리의 계단을 지운다
AI 코딩 도구가 주니어 개발자의 학습 경로를 무너뜨리고 있다는 실증 데이터 분석. Anthropic·METR 연구와 Amazon 사례로 보는 엔지니어링 커리어 사다리의 구조적 위기.
An important update 🚨 to the #METR study on developer #productivity using #AI – instead of 20% loss 📉, they now see a 20% gain 📈 in one year 🤯:
“We Are Changing Our Developer Productivity Experiment Design”, METR (https://metr.org/blog/2026-02-24-uplift-update/).
SWE-bench 통과한 AI 코드, 실제 개발자에겐 절반이 불합격
METR 연구 결과, AI가 SWE-bench를 통과한 코드의 절반이 실제 개발자 심사에서 탈락했습니다. 벤치마크 점수와 실무 유용성 사이의 격차를 분석합니다.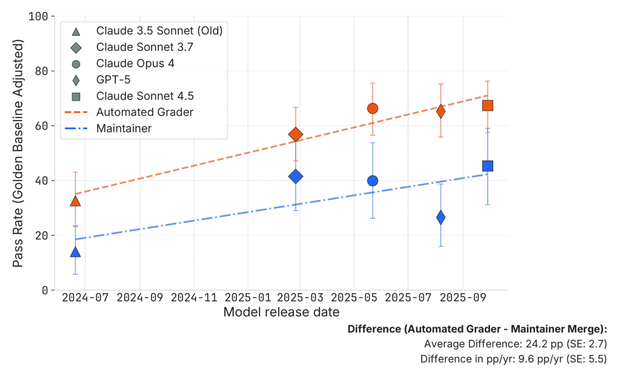
Вас пугают AI-увольнениями. Я посмотрел — кто это делает и зачем
Год назад METR доказали что AI замедляет разработчиков на 19%. В феврале 2026 обновили данные - похоже на разворот к ускорению. Но об этом почти не написали. Зато «AI уволит 50% разработчиков» - в каждом втором заголовке. Полез разбираться, кому выгодна AI-паника. Нашёл CEO, которые увольняют тысячи и тихо нанимают обратно. Нашёл вендоров, которые пугают увольнениями и одновременно открывают вакансии. И курсы «защити карьеру от AI» за $23 000.
https://habr.com/ru/articles/1017884/
#AI #страхономика #AIпаника #увольнения #продуктивность #METR #Klarna #Block
AI's Version of Moore's Law? - Computerphile
https://www.youtube.com/watch?v=evSFeqTZdqs
https://metr.org
Note that the success rate on the default chart is only 50% and for 80% the score is much lower. But the interesting part is indeed the rate of progress.
🚨 KI-Agenten exponentiell besser? METR zeigt steigende "Time Horizons" – aber 50% Erfolg = jeder 2. Versuch scheitert. Log-Skala: stabiler.
👉 Meine Einschätzung: Wirtschaftlich relevant, aber kein Beweis für baldige Agentenübernahmen.
(Picture Credits to METR, via metr org, abgerufen am 22.2.26, "Model Evaluation & Threat Research", Social-Media-Bearbeitung und Screenshot druch: Marlon Niklas Kaulich)