Jun Kim (@jundotkim)
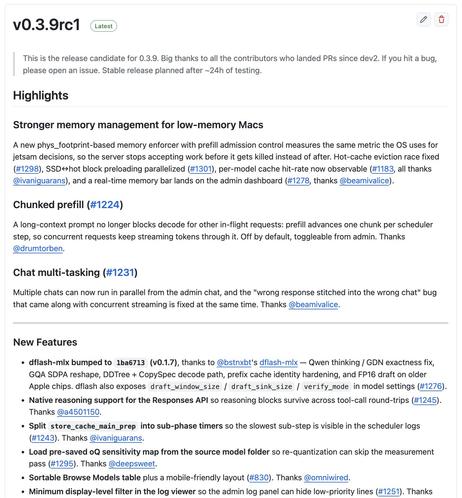
oMLX 0.3.9rc1이 릴리스됐다. 저메모리 Mac에서 OS 종료 방지 안정성 개선, DFlash v0.1.7 반영, Qwen의 thinking/GDN 수정, 긴 프롬프트가 다른 요청의 디코드를 막지 않도록 하는 chunked prefill 지원이 핵심이다. 로컬 LLM/MLX 운영에 실용적인 업데이트다.
Jun Kim (@jundotkim) on X
oMLX 0.3.9rc1 released. Highlights: - Low-memory Macs stay stable instead of getting killed by the OS - DFlash bumped to v0.1.7 (thanks to @bstnxbt's dflash-mlx). Qwen thinking/GDN fix, Etc. - Chunked prefill. A long prompt no longer blocks decode for everyone else -








