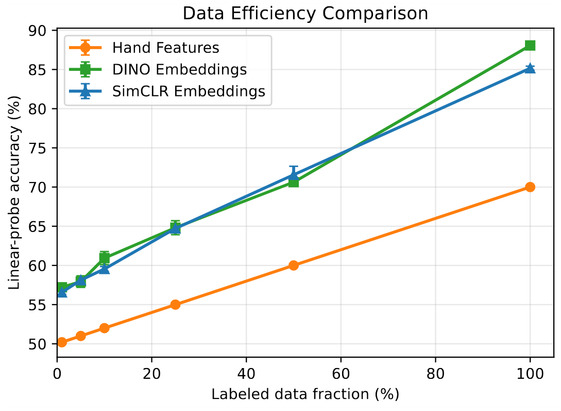
Наш «домашний» НИИ обошёл DINOv2, ViT и десятки ML‑моделей в сегментации видео
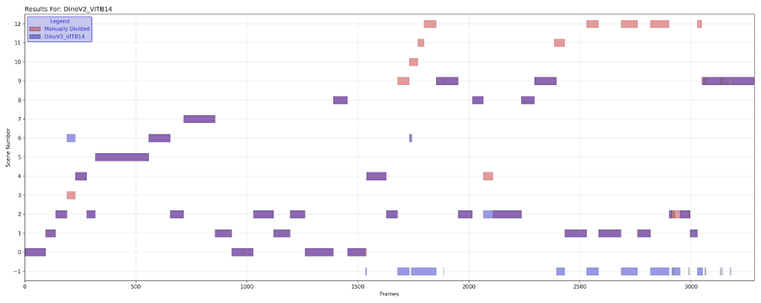
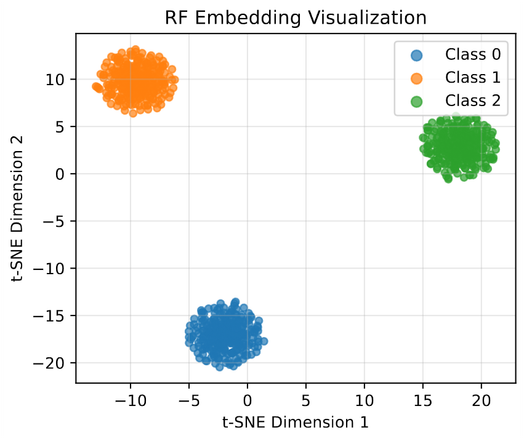
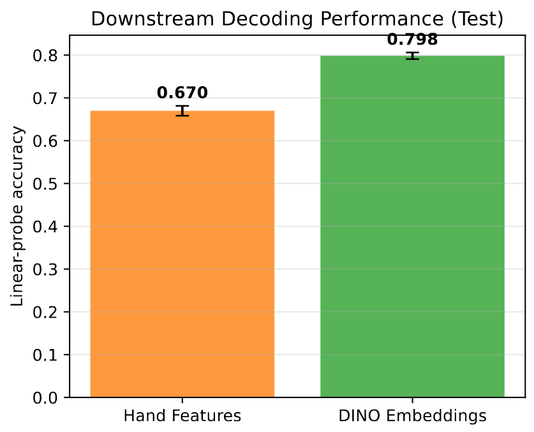
Мы открыли и разрабатываем новый способ обработки информации - TAPe (Theory of Active Perception, Теория активного восприятия). Работаем над ней давно, результаты мягко говоря впечатляющие, постепенно начинаем ими делиться. Немного писали о Теории на Хабре здесь . Исторически мы начали именно с обработки видео (когда-нибудь об этом расскажем). В этой статье покажем результаты сравнения разных методов обработки видео (гистограммы, Фурье, структурной похожести, ML-модели) и TAPe в задаче сегментации видео. TAPe в области компьютерного зрения - это Майк Тайсон и/или Майкл Джордан среди любителей (хорошо, еще не Майк Тайсон, но уже вполне себе Рокки Бальбоа). На фоне методов Теории даже супер прокаченные модели на стероидах растерянно сидят в углу ринга. (Ладно, пока что это все влажные мечты, мы даже еще не вышли толком на ринг; но, как мы помним, главное – это величие замысла). Читать как лажают ML с видео
https://habr.com/ru/articles/1007128/
#машинное_обучение #искусственный_интеллект #dbscan #dinov2 #computer_vision #фурье #sobel #гистограммы #гистограмма_направленных_градиентов #cnn