Ted (@tudoroancea)
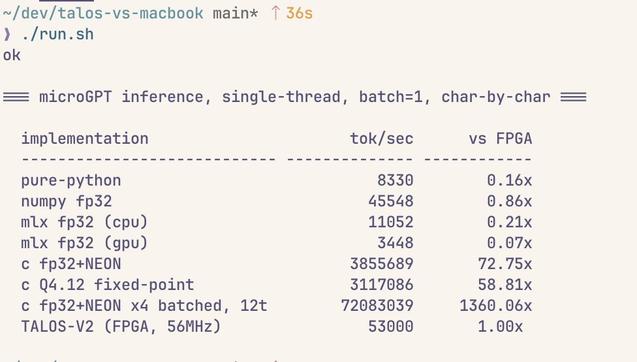
배칭을 더 늘리고 4개의 SIMD 레인과 12개 스레드(M4 Max의 12개 퍼포먼스 코어)를 활용한 최적화로 초당 7천만~8천만 토큰 처리 속도를 달성할 수 있다고 언급했다. 추론 성능 개선과 하드웨어 최적화에 관한 기술적 내용이다.
Ted (@tudoroancea)
배칭을 더 늘리고 4개의 SIMD 레인과 12개 스레드(M4 Max의 12개 퍼포먼스 코어)를 활용한 최적화로 초당 7천만~8천만 토큰 처리 속도를 달성할 수 있다고 언급했다. 추론 성능 개선과 하드웨어 최적화에 관한 기술적 내용이다.
Ivan Fioravanti ᯅ (@ivanfioravanti)
Ollama가 동시 요청에 대한 연속 배치(continuous batching)를 지원하는지 묻는 질문이다. LLM 서빙 성능과 처리량 최적화와 관련된 중요한 개발 도구 기능 문의로 볼 수 있다.
**Cách áp dụng Batching trong Llama.cpp? Tốc độ giảm theo LOL?** 🤔
@ClimateBoss chia sẻ trải nghiệm khi dùng lệnh `./llama-server --parallel 2 --cont-batching...` và gặp phải:
- Context bị giảm một nửa 😮
- 2 người dùng = 20% chậm hơn so với 1 người? 🤯
- Batching không hiệu quả như mong đợi?
NVIDIA nói tăng người dùng sẽ tăng tổng băng thông (throughput). Làm thế nào để tốc độ tăng lên? 🚀
#LlamaCPP #AI #Performance #Batching #MLOptimизация #ViệcLàmAI #TốcĐộ #Debug #NVIDIA #AIvn
What a Sustainable Workflow Looks Like for Chronic Pain: Real-Life Examples
Sustainable workflows prioritize adapting work habits to individual needs, especially for neurodivergent and disabled individuals. By recognizing that conditions and energies fluctuate, one can create a supportive, flexible routine that fosters productivity without burnout. Embracing rest and automation are essential strategies for maintaining creativity and honoring personal limits, ultimately leading to a more fulfilling work experience.
Why DeepSeek is cheap at scale but expensive to run locally
https://www.seangoedecke.com/inference-batching-and-deepseek/
#HackerNews #DeepSeek #Inference #Batching #Cheap #Expensive #To #Run #Local #Scale
I created a Simple Sprite Batcher for SFML. It batches them for you automatically and improves performance! Work with your normal sprites!
It's a part of my SFML Snippets repository on GitHub:
https://github.com/Hapaxia/SfmlSnippets
and also available on the SFML wiki:
https://github.com/SFML/SFML/wiki/Source:-Simple-Sprite-Batcher
The (small) class is there along with an example program.
Here's a video using it (excuse the compression issues):
Sprite batching in SFML https://youtu.be/2P13hhMgeFs?si=dbsmnlt7NqKhy4pJ