Кажется я обнаружил родину алфавита, цифр и китайских иероглифов
Современная наука утверждает, что первым алфавитом в мире был финикийский, произошедший от египетских иероглифов, а наши цифры были независимо разработаны в Индии.
Кажется я обнаружил родину алфавита, цифр и китайских иероглифов
Современная наука утверждает, что первым алфавитом в мире был финикийский, произошедший от египетских иероглифов, а наши цифры были независимо разработаны в Индии.
Скрытая грамматика: почему len() — это полисемия, а хороший код — набор идиом. Как филология объясняет «чистый код»
Оживленная дискуссия под моей первой статьей ( https://habr.com/ru/articles/940782/ ) показала: разговор о единстве языка со сферой программирования задевает многих за живое. Тем не менее, cпасибо всем за сотню комментариев, сохранений и невероятно полезного и ценного опыта! Однако язык — это не просто словарь, а динамическая система, в которой слова живут, взаимодействуют и порождают смыслы, выходящие за пределы их словарных значений. Следующим логическим шагом, таким образом, становится переход от статики «слова» (имени) к динамике «высказывания» (кода в действии). Вместе с тем один из наиболее сильных и частых аргументов от скептиков звучал примерно так: «весь код — это чистая, бездушная логика для машины». На мой взгляд, это самое большое заблуждение в этой индустрии. Знали ли вы, что оператор + в вашем коде семантически богаче, чем многие слова в русском языке? Или что конструкция if not my_list — это не просто синтаксис, а настоящая идиома, которая отделяет «носителя языка» от «иностранца»? Задача настоящей работы — исследовать, как в строго детерминированной среде кода возникают сложнейшие семантико-прагматические явления, свойственные живому языку. Давайте забудем про имена и заглянем в самое сердце кода — в его грамматику и риторику. Пристегните ремни безопасности :)
https://habr.com/ru/articles/941110/
#цифровая_филология #лингвистика #чистый_код #читаемость #идиомы #космотекст
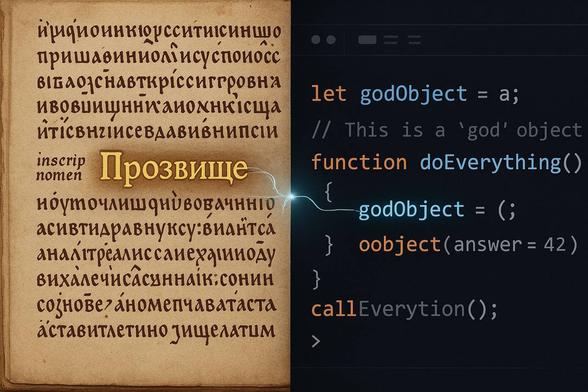
Привет, Хабр! Меня зовут Артем Лакомов, я филолог из МГУ. Да, вы не ослышались. И сегодня я хочу поговорить с вами о самой главной (и самой дорогой) боли в IT, но с совершенно неожиданной стороны....
Почему лучшие программисты — это филологи (сами того не подозревая). Что общего у переменной temp и прозвища «Очкарик»?
Привет, Хабр! Меня зовут Артем Лакомов, я филолог из МГУ. Да, вы не ослышались. И сегодня я хочу поговорить с вами о самой главной (и самой дорогой) боли в IT, но с совершенно неожиданной стороны. Каждый из вас хоть раз в жизни видел код, от которого хотелось плакать или же тихо ненавидеть свою работу. Код с переменными вроде data, res, temp. Код, где есть один гигантский класс, который делает абсолютно всё, и коллеги с любовью (или ужасом) называют его godObject. Все привыкли думать, что это просто «плохой стиль» или «технический долг». Но что, если я скажу вам, что это — не техническая, а языковая проблема? И что у монструозного godObject гораздо больше общего со школьным прозвищем «Толстый» , чем вы думаете? Последние несколько лет я занимаюсь тем, что применяю классическую лингвистику к программному коду. И я обнаружил поразительную вещь: правила, по которым вы даете имена переменным и классам, практически дословно повторяют законы, по которым в любом человеческом коллективе — от школьного класса до команды разработчиков — возникают прозвища. Давайте я покажу вам, как теория прозвищ, разработанная великим отечественным лингвистом А.В. Суперанской, вскрывает то, о чем инженеры только догадывались интуитивно, но, увы, не могли сформулировать.
https://habr.com/ru/articles/940782/
#цифровая_филология #коммуникация #лингвистика #чистый_код #именование #космотекст #компетенции_тимлида
Привет, Хабр! Меня зовут Артем Лакомов, я филолог из МГУ. Да, вы не ослышались. И сегодня я хочу поговорить с вами о самой главной (и самой дорогой) боли в IT, но с совершенно неожиданной стороны....
@anika_voin
- здесь хорошо спиться.
- "тся"
- "ться"!
Гонзо-репортаж, русская лингвистика и много плюсов: лучшее из хабраблога МойОфис за 10 лет
Ветеранам Хабра пора напрячься: время летит слишком быстро... В этом году нашему корпоративному блогу стукнуло 10 лет! За это время мы исследовали мир айтишки через самые разные сферы: от киберспорта и «фантазий о будущем» до классических технических «заглядываний под капот» с сотнями строк кода. В честь юбилея вспоминаем 10 лучших (по версии редакции) текстов — по одному на каждый год . Это статьи, без которых невозможно представить нас как команду и блог.
https://habr.com/ru/companies/ncloudtech/articles/939508/
#лингвистика #топ #подборка #подборка_статей #мойофис #дизайн #репортаж #c++ #тимбилдинг
5 слов из 5 букв
Делюсь с вами задачей, которая позволит бесцельно потратить ваше время, как уже это сделала со мной. Под катом небольшая история из жизни и немного кода на JS.
Этапы и принципы развития навыка говорения
Есть 2 разных способа говорения на иностранном языке. Они именно принципиально разные – как лазерная и струйная технологии печати. И нарабатываются по-разному. Непостижимым образом многие, кто мечтает «заговорить», этого не осознают. Речь пойдёт и о менее очевидных моментах развития навыка говорения. Это улучшенная версия старой статьи. «Гло́кая ку́здра ште́ко будлану́ла бо́кра и курдя́чит бокрёнка». Эту фразу из несуществующих слов предложил в начале XX века академик Л.В. Щерба. Из неё ясно, что «будлану́ла» — действие, которое ку́здра (ж.р.) совершила в отношении бо́кра (м.р.); бокрёнок, скорее всего, детёныш бокра. Для русского это очевидно сразу. Иностранцу придётся сначала выучить русский. Фраза показывает, что язык — это НЕ СЛОВА. Слова легко переходят из одного языка в другой. Язык — это принципы, по которым слова связываются друг с другом. В том, чтобы научиться говорить, ничего сложного нет — проблема это придуманная. А все неудачи от того, что люди, как говорится, put the cart before the horse, ставят телегу впереди лошади. Пытаются говорить, не понимая, как связываются слова в языке. Это как пытаться бегать, не научившись ходить. Не будем обсуждать руссо туристо, объясняющихся знаками и инфинитивами. Выделим три уровня «говорения»: 1-й уровень: говорим по-простому, но плюс-минус грамматически правильно. Например, не зная выражения «прикрой форточку», говорим проще: «закрой маленькое окно, но не до конца». 2-й уровень: говорим на конкретные темы именно теми фразами, которые используют носители языка («прикрой форточку»).
https://habr.com/ru/articles/933984/
#английский #английский_язык #английский_язык_изучение #самообразование #курсы_английского #русский_язык #лингвистика #единороги
«Девайс для супа». Почему мозг программиста зависает на простых словах
«Женя, передай вон тот… девайс для супа», - мой муж тыкает пальцем в ложку. Раньше я думала, что это стеб, но потом поняла: он реально не может переключиться после работы и вспомнить слово. Так я открыла «синдром забытой ложки» — бич многих знакомых айтишников. Узнать, как починить
Минификация кода для повышения эффективности LLM: влияние на лингвистику, генерацию и анализ программ
Большие языковые модели (LLM) становятся неотъемлемой частью инструментов генерации, анализа и автоматизации программирования. Их возможности позволяют автоматизировать разработку, искать ошибки, генерировать тесты, осуществлять перевод между языками программирования. Однако одно из ключевых ограничений – контекстное окно, то есть максимально возможная длина входных данных. С ростом объема современных программ эффективность работы LLM с длинным кодом становится всё более актуальной задачей, особенно учитывая вычислительные и финансовые издержки обработки длинных последовательностей. Минификация кода – процесс сокращения программного текста до минимального, необходимого для сохранения семантики. Для современных LLM это уже не только техническая задача (как раньше для web-ресурсов), а способ оптимизации использования ресурсов, экономия токенов, увеличение объема анализируемого кода, ускорение анализа и генерации. В данной статье рассматривается современное состояние исследований по минификации в контексте LLM, формулируются гипотезы о её влиянии, а также обсуждаются перспективы для программной лингвистики.
https://habr.com/ru/articles/931508/
#минификация #llm #токены #контекстное_окно #экономия_ресурсов #лингвистика

ВВЕДЕНИЕ Большие языковые модели (LLM) становятся неотъемлемой частью инструментов генерации, анализа и автоматизации программирования. Их возможности позволяют автоматизировать разработку, искать...




