Here is a way that I think #LLMs and #GenAI are generally a force against innovation, especially as they get used more and more.
TL;DR: 3 years ago is a long time, and techniques that old are the most popular in the training data. If a company like Google, AWS, or Azure replaces an established API or a runtime with a new API or runtime, a bunch of LLM-generated code will break. The people vibe code won't be able to fix the problem because nearly zero data exists in the training data set that references the new API/runtime. The LLMs will not generate correct code easily, and they will constantly be trying to edit code back to how it was done before.
This will create pressure on tech companies to keep old APIs and things running, because of the huge impact it will have to do something new (that LLMs don't have in their training data). See below for an even more subtle way this will manifest.
I am showcasing (only the most egregious) bullshit that the junior developer accepted from the #LLM, The LLM used out-of-date techniques all over the place. It was using:
- AWS Lambda Python 3.9 runtime (will be EoL in about 3 months)
- AWS Lambda NodeJS 18.x runtime (already deprecated by the time the person gave me the code)
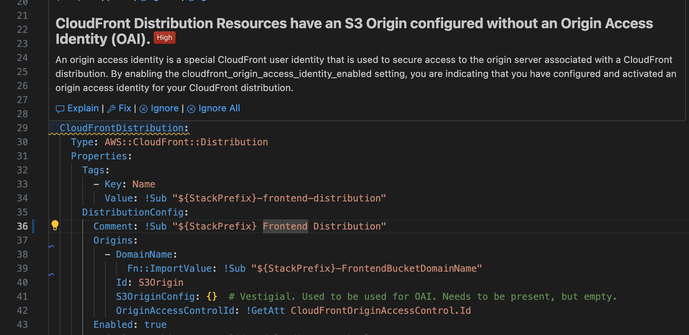
- Origin Access Identity (an authentication/authorization mechanism that started being deprecated when OAC was announced 3 years ago)
So I'm working on this dogforsaken codebase and I converted it to the new OAC mechanism from the out of date OAI. What does my (imposed by the company) AI-powered security guidance tell me? "This is a high priority finding. You should use OAI."
So it is encouraging me to do the wrong thing and saying it's high priority.
It's worth noting that when I got the code base and it had OAI active, Python 3.9, and NodeJS 18, I got no warnings about these things. Three years ago that was state of the art.