This is important to remember, especially in hard times

'On November 28th, 2012, Randall Munroe published an xkcd comic that was a calendar in which the size of each date was proportional to how often each date is referenced by its ordinal name (…) "In months other than September, the 11th is mentioned substantially less often than any other date. It's been that way since long before 9/11 and I have no idea why." After digging into the raw data, I believe I have figured out why.'
Das freie Web kollabiert gerade.
Die Zahlen, die Cloudflare-Chef Prince vorstellt, sehen düster aus. Bei Google enden inzwischen wohl 90 % aller Suchanfragen ohne Klick. Bei Antrophic kommt auf 60.000 Anfragen ein Klick. 🤯
https://the-decoder.de/cloudflare-boss-matthew-prince-hat-keine-guten-nachrichten-fuer-das-www/
Die Folien von @SemAntiKast zum Vortrag im Rahmen der Session KI+Veränderung heute Vormittag sind bereits online.
Beachtenswerte Infos zu den sozialen und Umweltfolgen der Nutzung von #KI .

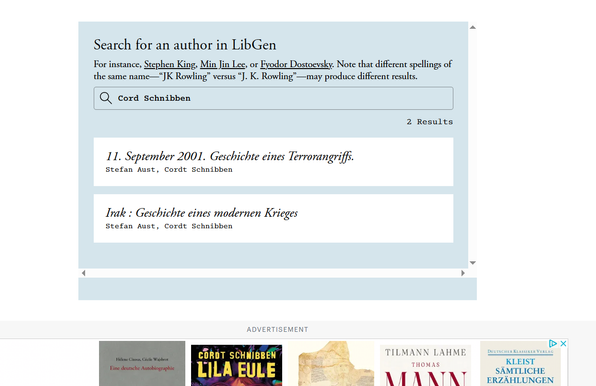
@hipsterl0s sich soweit wie möglich nicht auf Artikel in der Cloud zu verlassen, sondern Artikel (für den Privatgebrauch) herunterladen & mit Metadaten versehen :)
Die dann zu Teilen ist ein größeres (juristisches) Problem...
@mob @Lambo hier ist ein repo mit den deutschen Texten: https://codeberg.org/Schoeneh/oer-schattenbibliotheken
@Lambo @benkaden @leibnizopenscience super wichtig für Forschung.
viel zu viele Ressourcen (auch Steuergelder) fließen in die Journale welche selbst nahezu nichts machen bzw. fast die gesamte Arbeit an Unbezahlte weitergeben und wiederum Milliarden an Profite haben.
Das sind die Bremsen die Forschung und die oben genannten freien Blibliotheken lösen diese Bremsen
@Lambo @benkaden @leibnizopenscience
Ich halte Paywalls für problematisch und auch die Schattenbibliotheken finde ich nicht unproblematisch.
Woher weiß ich, dass da nicht Fake Artikel enthalten sind?
Wenn ich kein Abo bei den Orginal Seiten habe, kann ich nicht wissen und nicht prüfen, ob ich dort nicht vielleicht ein Fakeartikel abrufe, der so gar nicht auf der Originalseite veröffentlicht wurde.
Vertrauen ist gut, Kontrolle ...?
Damit damit sprichst du direkt den wunden Punkt an.
Ich kann es nicht prüfen ohne Abo. Aufgrund der Medienvielfalt, würde es sicherlich auch ein teures Unterfangen werden. Sich umfassend zu informieren wird immer mehr zu einem Luxus, sowohl finanziell als auch zeitlich.
Wer prüft die Einträge in eine Schattenbibliothek und wie kann Vertrauen hergestellt werden?
Welche "Schattenbibliothek" ist vertrauenswürdig? Wie wird das sichergestellt, in Zeiten eines hybriden Krieges?
Ich verstehe worauf dein Argument abzielt und auch das ist eine Möglichkeit der Desinformation.
Eine Schattenbibliothek erweitert jedoch den Möglichkeitsraum, von Desinformation.
Wie du präferiere auch ich Open Access, doch da bleibt das Spannungsfeld der Finanzierung von arbeitsintensiven Inhalten und das scheint mir kein einfach zu lösendes Problem.
Ich halte das Szenario einer Manipulation von Artikeln in Schattenbibliotheken zwar nicht für ausgeschlossen, aber für sehr unwahrscheinlich. Der Aufwand für die Erstellung und Streuung und der potentielle Ertrag, d.h. dass jemand diese Artikel auch wirklich findet und "nachnutzt", dürften in keinem Verhältnis stehen. Sci-Hub hat meines Wissens auch keinen allgemeinen Upload-Button. Dadurch sind die Manipulationsmöglichkeiten ebenfalls begrenzt.
Zur Qualitätsprüfung: Jeder wissenschaftliche Text sollte ohnehin kritisch und auf Plausibilität hin gelesen und bewertet werden.
Über OpenAlex kann man sich auch Kontextinformationen zu Autor*innen und Zitationen heranholen. Das hilft bei der Einschätzung.
Generell halte ich die Gefahr einer Manipulation wissenschaftlicher Diskurse durch predatory journals oder gefälschte Zeitschriften bzw. "fake paper" übrigens für deutlich höher.
@nina @benkaden @awinkler @Lambo
Bedenkenswerte Nebeneffekte
"The investigation revealed that 84.83% of the retracted articles available on Sci-Hub do not have any indication of their retracted status."
https://pubmed.ncbi.nlm.nih.gov/39743744/
"The persistence of error: a study of retracted articles on the Internet and in personal libraries"
https://pmc.ncbi.nlm.nih.gov/articles/PMC3411255/
https://greenelab.github.io/scihub-manuscript/v/8fcd0cd665f6fb5f39bed7e26b940aa27d4770ba/
Zurückgezogene Studien schlecht identifizierbar
https://irishinneburg.de/zurueckgezogene-studien-schlecht-identifizierbar/

This study underscores the crucial need for stringent implementation of regulatory measures on retraction suggested by the Committee on Publication Ethics (COPE) or newly published National Information Standards Organization (NISO) recommendations.
@Rene_M_G @nina @awinkler @Lambo
Dann ist es aber ja gerade kein spezifischer Einwand gegen Schattenbibliotheken, oder?
Ich denke, dass Schattenbibliotheken auf ihre Art und unvermeidlich auch die ganze Bandbreite der Probleme des generellen wissenschaftlichen Publizierens mit spiegeln. Daraus kann man ihnen jedoch m.E. keinen Vorwurf machen. Ihr Anliegen ist ja einzig, den Aspekt der Zugänglichkeit der Volltexte zu adressieren.
Danke für die Ergänzung.
Das Hauptproblem, das vermutlich auch @Rene_M_G umtreibt, bleibt aus meiner Sicht, inwiefern Nicht-Expert*innen, die Schattenbibliotheken ja auch gern nutzen, diese Effekte (und Lösungen) kennen, verstehen und reflektieren. Also, wenn man so will, die schattenbibliotheksspezifische Informationskompetenz. Was uns ja zurück zum Anliegen des Posters bringt...
@Lambo @benkaden @leibnizopenscience
Tolles Poster 🤩🙏
@Lambo @benkaden @leibnizopenscience
Wie ähnlich oder unterschiedlich sind die (moralischen) Positionen verschiedener Schattenbibliotheken?
Gibt es z.B. welche, die versuchen, nur Literatur bereitzustellen, bei denen Autor*innen und Kleinverlage nicht unter Piraterie leiden?
@JonasJRichter @Lambo @leibnizopenscience
Das ist mir nicht bekannt. Allerdings findet sich in den Schattenbibliotheken, die ich kenne, vor allem wissenschaftliche Literatur (sci-hub) und ein Potpourri an, nun ja, Freizeit-Scans älterer Quellen, wie man sie auch z.B. archive.org findet (LibGen). Aktuelle Literatur kleiner Publikumsverlage ist mir noch nie begegnet. Ebenso wenig das aktuelle Suhrkamp-Taschenbuch-Programm.
@Lambo @JonasJRichter @leibnizopenscience
Das stimmt. Für aktuelle Bücher mit Bremen-Bezug muss man allerdings nach wie vor auf die Werbeanzeige klicken...
Für vergriffene und verwaiste Werke ist es auch aus meiner Sicht mitunter tatsächlich eine Option. Aber auch dazu würde ich zunächst erst zu Archive.org bzw. im Zweifel einem Online-Antiquariat gehen. (Oder, natürlich, in eine Bibliothek.)