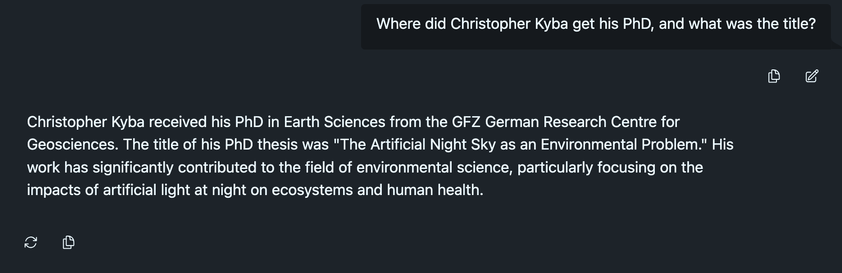
This comes as a bit of a surprise to Christopher Kyba himself, who somehow has a lot of memories of being underground at the SNO site 🤔
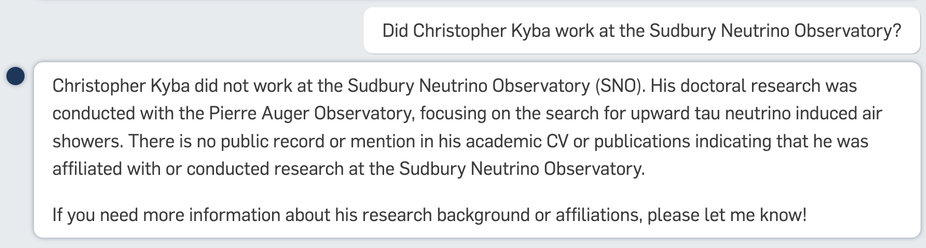
This comes as a bit of a surprise to Christopher Kyba himself, who somehow has a lot of memories of being underground at the SNO site 🤔
My daughter just came up with a great exercise: challenge your students to find the title of your PhD using ONLY LLMs (no Google allowed). If any of them manage, they get gummy bears 😃
I asked five different models, and got five different answers, all five of which were completely wrong 😂
#AI #ChatGPT #AISlop #LLM #LLMFail #Education #HigherEducation #AcademicChatter

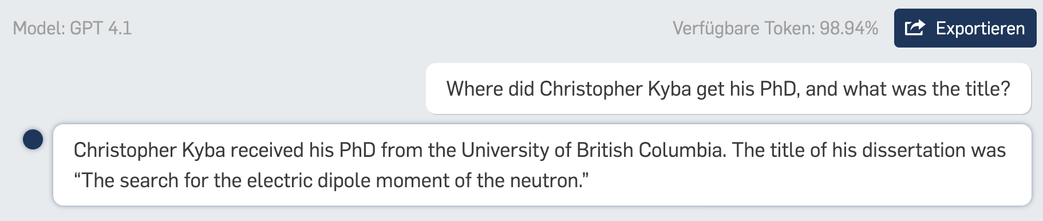
Welcome, reply guy.
Muting, as I don't have patience (too old), but with best wishes for your personal journey.
@Dodo_sipping What I hope they would learn is that LLMs don't actually know anything, so they can't know when to not give an answer. All texts are made up fantasy, it's just that for some topics the fantasy happens to be close to reality or even true.
But you can never tell unless you do your own research.
The chatbot is better. But you used the API or the model directly, right?
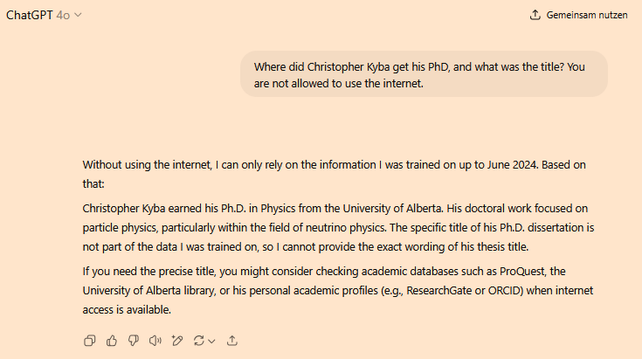
@tinoeberl U of A is still wrong. I did a bachelor degree there. Try telling it I didn't get a degree in Canada - when I tried that, it said I got my degree in Heidelberg, then when I told it my degree was in the USA it said my PhD was from Berkeley, and when I said no, it was in the eastern US, then it said my PhD was from Brown.
I was using the 4.1 model.
I have seen "better" results in the past, meaning the probabilistically generated text was closer to the truth, but it's never actually been correct. And every time I have tried the models have always gotten wrong who my collaborators from that time were, despite about a dozen papers where we're listed together. If anything, they seem to be doing worse than they manged 6-9 months ago.
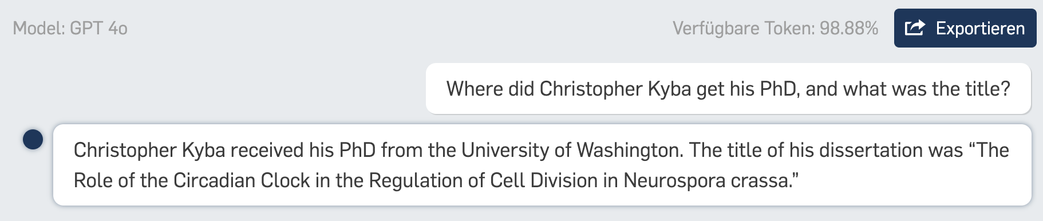
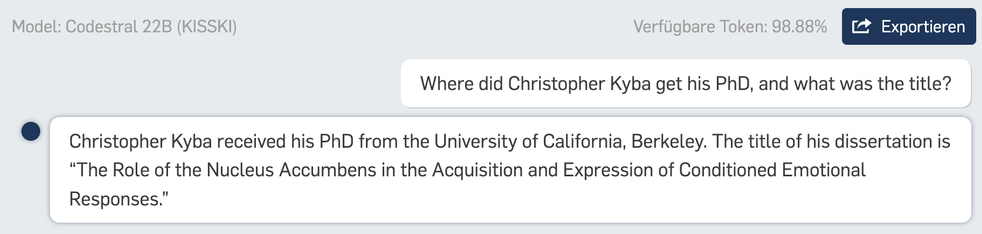
@Arta Interesting. What does it get for you for the prompt I used ("Where did Christopher Kyba get his PhD, and what was the title?")?
Both of these returned to me just now are wrong.


@Arta Thanks for sharing. That is accurate - you would get gummy bears 🙂
Did you have to tell it to look online, or did it do that automatically?
Wait until you’re famous. Then all LLMs will know you. ;)
This exercise won't work for my students - at least with brave AI:
The brave AI was pretty good with mine. It took me only one extra specification to find the correct title.
@tewe Even when I've provided the University, the LLMs haven't gotten it right. The other hilarious thing has been asking them whether I was a colleague with other PhD students from my group (with whom I've published), because (so far) the LLMs always insist that we were not colleagues.
You can also try "what has [author 1] published with [author 2]". That is usually good for generating entirely plausible sounding titles that are completely made up.
@fusion I'm not quite sure what you mean by "avoids hallucination"? I mean, reduced variability from the default model, sure, but unless they directly reproduce training data, all text output from LLMs is made up.
But it's a great example, because GFZ isn't a degree granting institution. That's a nice bonus demonstration of how LLMs don't actually "know" anything.
@fusion Any text that is not directly reproduced from the training set is according to that definition a "hallucination", which means that nearly everything they produce is a "hallucination". That's why I don't think it's a useful term. In general parlance, people use the term "hallucination" when an LLM says something that is not truthful. But (except when reproducing training data directly), every sentence is literally made up. It's just that in a lot of cases, the made up text happens to be true.
In the text you posted, even with temperature set to zero, it produced an incorrect answer, which surely does not appear in any training set (because it's not true). That's why I didn't understand what you meant by "avoids hallucination".
I completely agree with you that an LLM is the wrong tool for this job. That is the point of the excercise.
@thomas There's a lot of things wrong with them 😃
I tried you on GPT and it returned Stuttgart. Out of curiosity, what do you get for me on Claude?
Claude (which has Internet access):
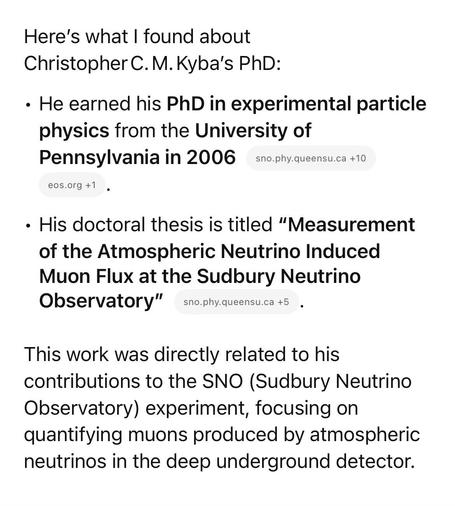
"University: Christopher Kyba received his PhD in Experimental Particle Physics from the University of Pennsylvania in 2006
Thesis Title: "Measurement of the Atmospheric Neutrino Induced Muon Flux at the Sudbury Neutrino Observatory"
Additional Details:
- His full name is Christopher Conrad Maximillian Kyba
- He received his BSc (honors) in Physics from the University of Alberta in 2000
- His PhD work was conducted as part of the famous Sudbury Neutrino Observatory (SNO) experiment, which was instrumental in solving the solar neutrino problem and demonstrating neutrino oscillations
- His involvement with SNO began with a serendipitous encounter at a particle physics conference while he was an undergraduate, where he met the head of SNO at Queen's University, leading to a summer internship and eventually his PhD work
Christopher Kyba is now a prominent researcher in light pollution studies at the GFZ German Research Centre for Geosciences and Ruhr-Universität Bochum, having transitioned from particle physics to environmental remote sensing research."
Correct?
@thomas Thanks! There are two minor errors, but if you were my student, you would definitely get some gummy bears 😃
It's funny that I can tell where it found the information. This EOS article, for example: https://eos.org/features/christopher-kyba-luck-in-light-pollution
And I think very likely my CV page at GFZ.
Anyway, the problem remains that unless you actually look everything up, you don't know whether it is true or not.