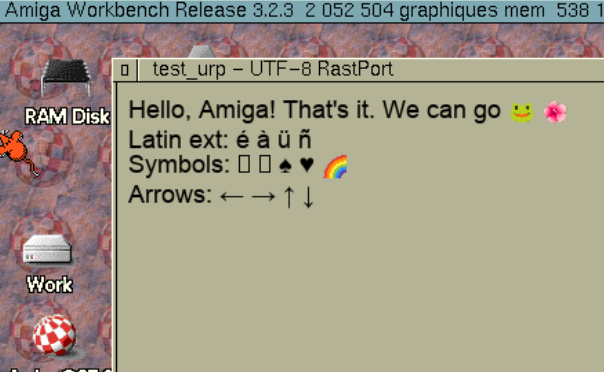
🎬 Ok, here we are: 🎺 First official release of 🎺 #EmojiGear 0.9b, likely the first 🥇 #UTF-8 #Unicode #Amiga #AmigaOS3 3.2 (soon 3.9)text editor 👀. This is also the first release for utf8rastport.library, an Amiga shared library 📖 that manages multiple fallback truetype fonts, metrics, and rendering on Amiga Intuition "RastPorts". Also first release for shared BOOPSI gadget class UniTextEditor.gadget, that is the active part of EmojiGear 🚀. @Amiga_News @amigaimpact
https://github.com/krabobmkd/EmojiGear/releases/tag/r09b
Note: This architecture potentially allows to display and edit actual modern text encoding and emojis in further IRC clients, mailers, mastodon clients, consoles, etc...
https://github.com/krabobmkd/EmojiGear/releases/tag/r09b
Note: This architecture potentially allows to display and edit actual modern text encoding and emojis in further IRC clients, mailers, mastodon clients, consoles, etc...