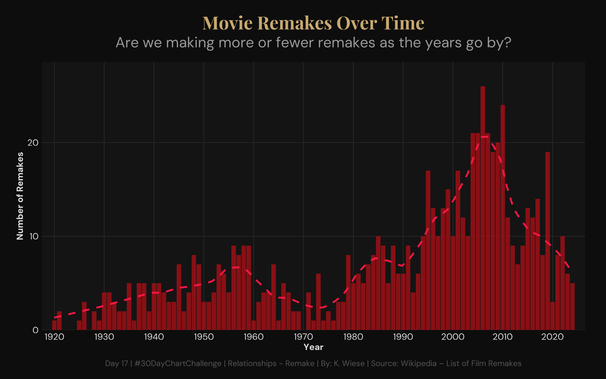
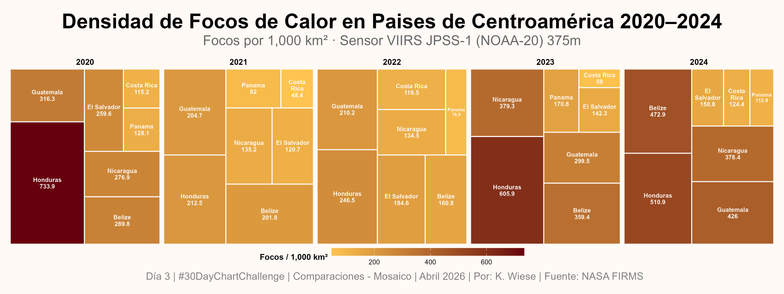
#Day17 | Relationships – Remake | #30DayChartChallenge | Are we making more or fewer remakes as the years go by?. Built with #RStats using #rvest, #dplyr, #stringr, #ggplot2 and #showtext.
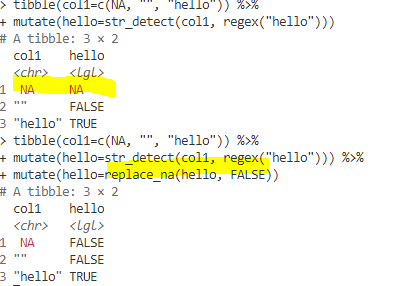
Question to #rstats enthusiasts: How are you dealing with NAs when using #str_detect?
str_detect(NA, regex("hello")) results in NA. This is expected behavior and I think I get the reasoning behind it.
In 99 % of my usecases though, I would like to have a FALSE as a result. Hence I need everytime an additional step to convert NAs to FALSE. I find this combersome.
I was wondering how others are dealing with such cases. Sometimes I think a pertaining option in #stringr would be nice....
This is a noob's observation of R, Tidyverse and Stringr. But wow, why can some datasets open in notepad or Windows file preview or excel in 1 second but takes minutes or hours to show up in str_view_all?
The {stringr} #rstats 📦 gets a function to convert a character vector into a single, comma-separated string *with custom wording before the last item.* (I've been using knits::combine_words() for that.)
Example from the tidyverse blog post about stringr 1.5.0:
str_flatten_comma(c("cats", "dogs", "mice"), last = ", and ")
#> [1] "cats, dogs, and mice"
