JRuby 9.4.15.0 출시 및 9.4.x 시리즈 지원 종료(EOL)
JRuby 9.4.15.0 버전이 출시되었으며, 이번 릴리스를 기점으로 JRuby 9.4.x 시리즈의 공식 지원이 종료(EOL)된다.
#jruby
https://ruby-news.dev/articles/jruby-9-4-15-0-released-9-4-x-is-now-eol
JRuby 9.4.15.0 출시 및 9.4.x 시리즈 지원 종료(EOL)
JRuby 9.4.15.0 버전이 출시되었으며, 이번 릴리스를 기점으로 JRuby 9.4.x 시리즈의 공식 지원이 종료(EOL)된다.
#jruby
https://ruby-news.dev/articles/jruby-9-4-15-0-released-9-4-x-is-now-eol
JRuby 9.4.15.0 출시 및 9.4.x 시리즈 지원 종료(EOL)
JRuby 9.4.15.0 버전이 출시되었으며, 이번 릴리스를 기점으로 JRuby 9.4.x 시리즈의 공식 지원이 종료(EOL)된다.
RubyConf Austria 2026: Glimmer DSL을 활용한 프론트엔드 Rails 개발 발표
RubyConf Austria 2026에서 Glimmer DSL for Web을 활용해 JavaScript 사용을 최소화하고 Ruby로 프론트엔드를 개발하는 방법을 발표했다.
#jruby
https://ruby-news.dev/articles/code-master-blog-presentation-slides-for-rubyconf-austria-2026-talk-frontend-ruby-on-rails-with-glimmer-dsl-for-web
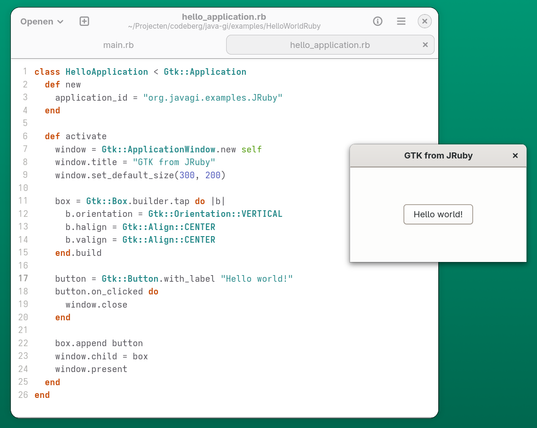
Finally set out to write a couple #ruby #gtk apps with #JRuby for the java-gi examples repository.
Really impressive how easy #JRuby it makes to integrate ruby with java.
Across the spread on page twenty-nine, the man behind @JRuby left his blessing in bright pink:
> Ruby and JRuby, friends forever! Keep Ruby Chunky!
> Charles Nutter
@headius would have it no other way.
#whysfoxes #WhysPoignantGuideToRuby #WPGTRPage29 #ruby #jruby #chunkybacon #RubyLanguage #RubyLang

Charles Nutterさん「Twenty Years of JRuby」 〜RubyKaigi 2026 2日目キーノート
https://gihyo.jp/article/2026/05/rubykaigi-2026-keynote-report-day2?utm_source=feed
#gihyo #技術評論社 #gihyo_jp #RubyKaigi_2026 #Ruby #Matz #プログラミング #JRuby #Ruby_on_Rails #Java
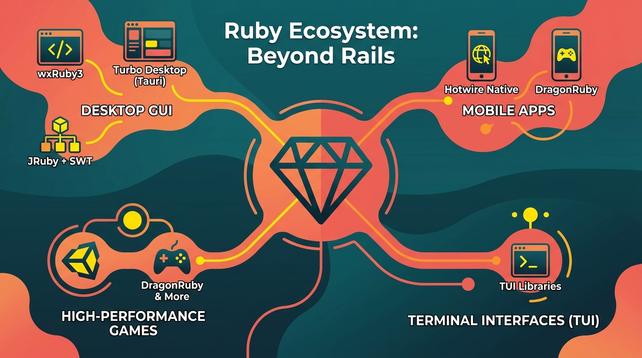
Ruby로 만드는 크로스 플랫폼 애플리케이션 가이드: 데스크톱, 모바일, TUI
Ruby는 Rails 외에도 데스크톱 GUI, 모바일 앱, 고성능 게임 엔진, 터미널 인터페이스(TUI) 개발을 위한 다양한 라이브러리 생태계를 보유하고 있습니다.
#jruby
https://ruby-news.dev/articles/ruby-everywhere-a-guide-to-cross-platform-libraries-fascination-works
JRuby의 미래: IR 아키텍처와 성능 최적화 (RubyKaigi 2013)
JRuby는 AST 기반 실행에서 벗어나 레지스터 기반의 새로운 내부 표현(IR) 아키텍처로 전환하여 성능과 최적화 효율을 극대화한다.
#jruby
https://ruby-news.kr/articles/the-future-of-jruby-rubykaigi-2013
JRuby의 미래: IR 아키텍처와 성능 최적화 (RubyKaigi 2013)
JRuby는 AST 기반 실행에서 벗어나 레지스터 기반의 새로운 내부 표현(IR) 아키텍처로 전환하여 성능과 최적화 효율을 극대화한다.
krypt: Ruby를 위한 차세대 암호화 프레임워크와 설계 철학
기존 OpenSSL API의 복잡성과 오용 가능성을 해결하기 위해 개발자 친화적인 고수준 인터페이스와 저수준 제어 기능을 동시에 제공한다.
#jruby
https://ruby-news.kr/articles/krypt-semper-pi-rubykaigi-2013


 gihyo.jp
gihyo.jp