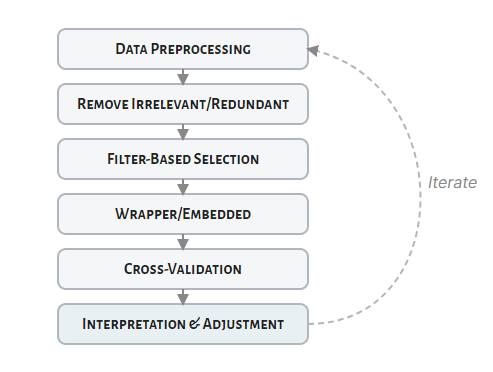
Title: P2: I have been reading about "feature selection" for ML. [2024-10-13 Sun]
- http://www.feat.engineering/feature-selection
蠡 #ml #machinelearning #datascience #dailyreport #featureselection
- http://www.feat.engineering/feature-selection
蠡 #ml #machinelearning #datascience #dailyreport #featureselection
1.4 Feature Selection | Feature Engineering and Selection: A Practical Approach for Predictive Models
A primary goal of predictive modeling is to find a reliable and effective predic- tive relationship between an available set of features and an outcome. This book provides an extensive set of techniques for uncovering effective representations of the features for modeling the outcome and for finding an optimal subset of features to improve a model’s predictive performance.