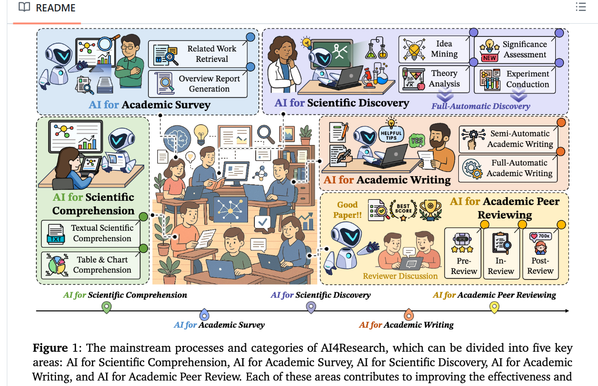
Assessing open access scholarly journals for integration into artificial intelligence research assistants
#ArtificialIntelligence #Consensus #Elicit #HeatherMoulaisonSandy #JennyBossaller #OpenAccess #OpenAccessJournals #SanjaGidakovic #ScholarlyJournals