merve (@mervenoyann)
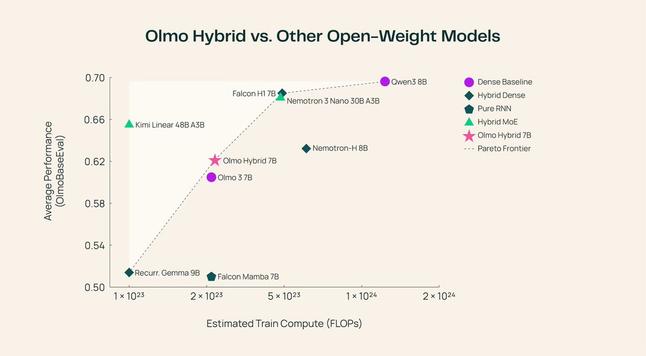
Allen Institute for AI(AI2)가 Olmo Hybrid 모델군(base/SFT/DPO)을 공개했습니다. 이 모델군은 트랜스포머와 RNN 레이어를 혼합해 FLOP 대비 학습 효율이 높은 구조를 추구하며 학습 측면에서 파레토 프런티어에 위치한다고 주장하고 확장성도 확보했다고 보고했습니다. 또한 학습 데이터 믹스도 함께 공개되었습니다.
merve (@mervenoyann)
Allen Institute for AI(AI2)가 Olmo Hybrid 모델군(base/SFT/DPO)을 공개했습니다. 이 모델군은 트랜스포머와 RNN 레이어를 혼합해 FLOP 대비 학습 효율이 높은 구조를 추구하며 학습 측면에서 파레토 프런티어에 위치한다고 주장하고 확장성도 확보했다고 보고했습니다. 또한 학습 데이터 믹스도 함께 공개되었습니다.
Yoav HaCohen (@yoavhacohen)
LTX-2가 오픈-웨이트 비디오 모델 부문에서 1위를 기록했다는 트윗입니다. @ArtificialAnlys Video Arena에서 텍스트→비디오 및 이미지→비디오에서 최고 성능을 보였고, 오픈 웨이트·빠른 추론·효율적 훈련 등 모델 특성을 강조합니다.
https://x.com/yoavhacohen/status/2008932234795864560
#ltx2 #videomodel #openweights #fastinference #efficienttraining
🚀 **MiniModel-200M-Base**: Mô hình AI nhỏ nhưng mạnh mẽ!
- Được đào tạo chỉ trong **1 ngày** với **10 tỷ token** trên **máy RTX 5090 duy nhất**.
- Kỹ thuật hiệu suất cao: **Adaptive Muon optimizer**, **Float8 pretraining**, **ReLU² activation**, **Bin-packing**.
- Hiệu suất ấn tượng: setup được **Fibonacci** và **các chữ số của π**.
Mô hình này đang có cộng đồng và giấy phép **Apache 2.0**.
#AI #MáyHọc #MiniModel #HuggingFace #LLM
#MachineLearning #EfficientTraining #AIModels
https://ww

Diffusion models have emerged as the mainstream approach for visual generation. However, these models typically suffer from sample inefficiency and high training costs. Consequently, methods for efficient finetuning, inference and personalization were quickly adopted by the community. However, training these models in the first place remains very costly. While several recent approaches - including masking, distillation, and architectural modifications - have been proposed to improve training efficiency, each of these methods comes with a tradeoff: they achieve enhanced performance at the expense of increased computational cost or vice versa. In contrast, this work aims to improve training efficiency as well as generative performance at the same time through routes that act as a transport mechanism for randomly selected tokens from early layers to deeper layers of the model. Our method is not limited to the common transformer-based model - it can also be applied to state-space models and achieves this without architectural modifications or additional parameters. Finally, we show that TREAD reduces computational cost and simultaneously boosts model performance on the standard ImageNet-256 benchmark in class-conditional synthesis. Both of these benefits multiply to a convergence speedup of 14x at 400K training iterations compared to DiT and 37x compared to the best benchmark performance of DiT at 7M training iterations. Furthermore, we achieve a competitive FID of 2.09 in a guided and 3.93 in an unguided setting, which improves upon the DiT, without architectural changes.
📢 New research from Google DeepMind on JEST: a way to train AI models 13x faster and 10x more energy-efficient than current techniques. 🌍💻 Reduce AI's environmental impact & mitigate carbon footprint.
#SustainableAI #EfficientTraining https://www.maginative.com/article/google-deepmind-unveils-jest-a-new-ai-training-method-that-slashes-energy-use/