Qiita - 人気の記事
Qiita - 人気の記事Голосовой КПТ-дневник с распознаванием речи на устройстве: Flutter и on-device Whisper
Эта статья про то, как я сделал голосовой дневник мыслей для когнитивно-поведенческой терапии, почему распознавание речи у меня крутится прямо на телефоне, и какие на этом пути были технические развилки. Кода почти не будет, будет архитектура и обоснование решений. Я сам прошёл через тревожные расстройства, панические атаки и несколько депрессивных периодов. Из всего, что мне помогало, переломной стала КПТ, и у неё есть домашняя часть, дневник мыслей, который нужно вести между сессиями. Вести его текстом в момент тревоги у меня не получалось годами, и в какой-то момент я понял, что хочу диктовать его голосом. Так появился проект, который я тут и разбираю.
https://habr.com/ru/articles/1043432/
#Flutter #Whisper #whispercpp #ondevice #распознавание_речи #Dart #КПТ #мобильная_разработка

🚨 NEWS: Flutter da zero: installazione Dart, primo widget e hot reload — Guida operativa
Ecco i punti chiave in breve:
💡 Stai installando Flutter da un'ora e il comando flutter doctor ti dà ancora errori a pioggia. Oppure hai già l'SDK funzionante ma non capisci come funziona il ciclo di sviluppo: scrivi codice, salvi,...

🔴 #HumpdayQandA and Live Coding! in 30 minutes at 5pm BST / 6pm CEST / 9am PDT today! Answering your #Flutter and #Dart questions with @simon @randalschwartz @danicox @johnwiese

Humpday Q&A/AMA and Live Coding! ::3rd June 2026 :: #HumpdayQandA #Flutter #FlutterCommunity
What is up my fellow beings. I'm super excited to say that my journal article and software package have now been officially published in the Journal of Open Source Software!! 


Thanks to the editor, editor-in-chief and the excellent reviewers 
#lsl #labstreaminglayer #dart #foss #oss #opensource #flutter
JOSS (@[email protected])
Just published in JOSS: 'Liblsl.dart: A Dart native API for Lab Streaming Layer (LSL)' https://doi.org/10.21105/joss.10425
#AutomatenWagner - 5,90 € #Gutschein #Rabattcode #Coupon #Dart | MKW: 60 € https://www.preishals.de/gutscheine/automatenwagner/

🎯 Dart 3.12 finally fixes private named parameters - a bug that should have never existed. Plus: primary constructors, Genkit AI, Firebase Functions in Dart.
Link in the comment

DartがサーバレスのCloud Functions for Firebaseに対応、Dartはフルスタック言語へ。事前コンパイルでコールドスタートが10ミリ秒
https://www.publickey1.jp/blog/26/dartcloud_functions_for_firebasedart10.html

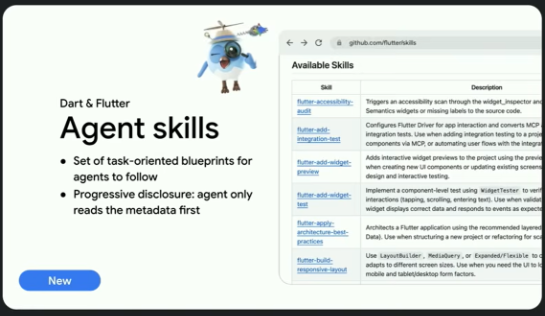
Google、「Dart&Flutter Agent Skills」リリース。DartとFlutter開発の最新ベストプラクティスをAIエージェントに提供
https://www.publickey1.jp/blog/26/googledartflutter_agent_skillsdartflutterai.html